
TL;DR
- An AI visibility audit measures how often and how well a brand appears across ChatGPT, Perplexity and Gemini for the queries that matter to it.
- The method has ten steps grouped into three phases: scope the queries, measure the current state, then score and prioritise.
- A defensible audit uses a fixed query template spread across awareness, consideration and decision intent, sampled repeatedly per engine.
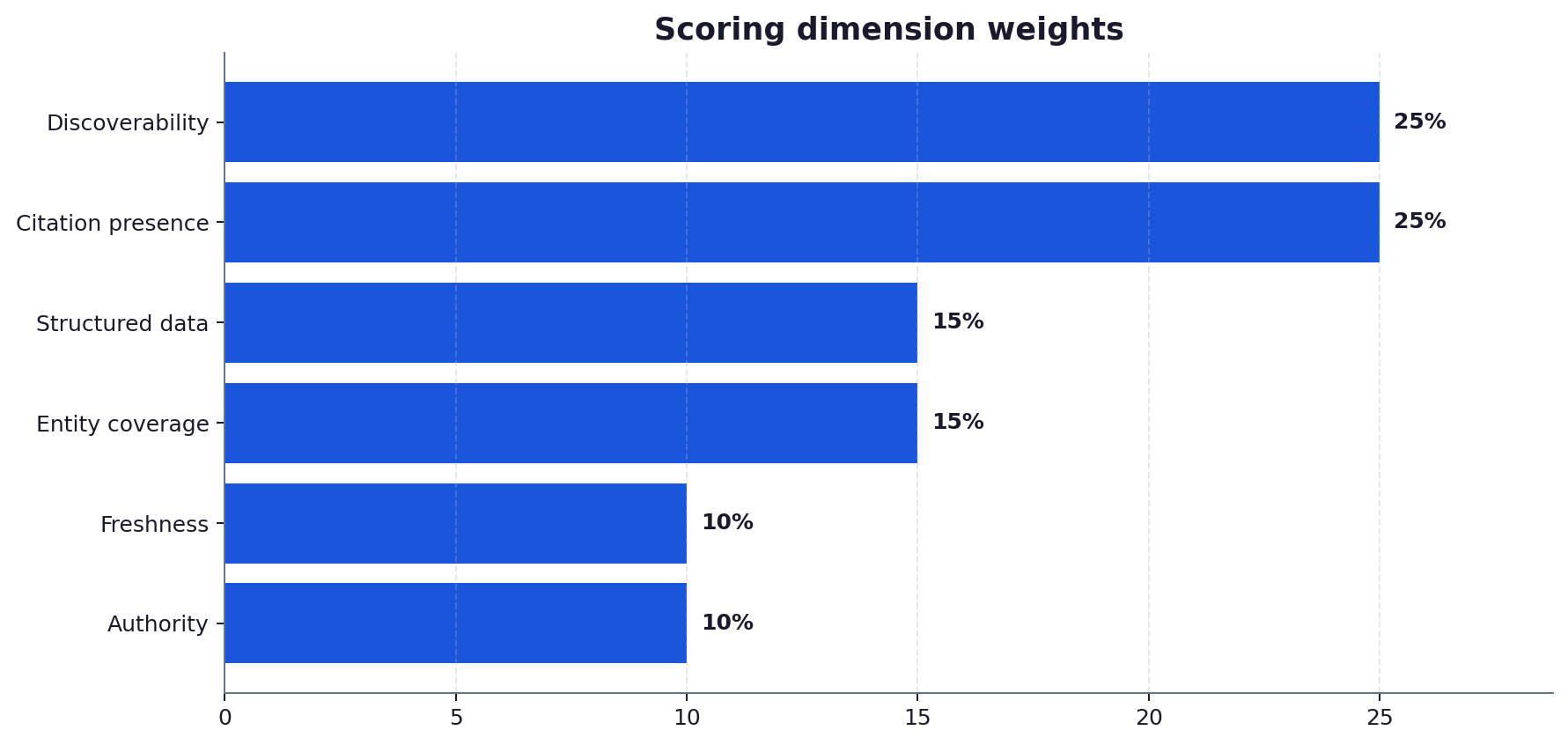
- Scoring rests on six weighted dimensions: discoverability, citation presence, structured data, entity coverage, freshness and authority.
- The output is a single visibility score plus a ranked fix list, repeatable enough that two analysts auditing the same site land close together.
Key facts
- Generative visibility is measurable across a query set rather than on a single lookup, which is the basis for any repeatable audit (Aggarwal et al., 2024).
- Citation share, the proportion of relevant answers that cite a brand, is the core metric the audit tracks (AiBoost, 2026).
- AI answer sets change between identical prompts, so each query must be sampled several times per engine (Ahrefs, 2026).
- Tools such as Profound make repeated cross-engine measurement practical at scale (Profound, 2026).
- Structured data and entity coverage are auditable inputs that engines demonstrably weigh (Schema.org, 2026; Google, 2026).
What an AI visibility audit actually measures
An AI visibility audit answers one question: when a buyer asks an AI engine something this brand should win, does the brand appear, and if not, why. That is different from a traditional SEO audit, which checks rankings and technical health. Here the unit is the answer, and the metric is how often the brand is cited or recommended across a defined query set. The original GEO research established that this visibility is measurable across many queries, which is what makes a repeatable method possible.
The framework below generalises the methodology behind our own GEO Audit product, redacted of the proprietary scoring weights. Any agency can copy the structure. The discipline that makes it useful is consistency: the same queries, the same engines, the same sampling and the same rubric every time, so results are comparable across audits and across analysts.
Phase one: scope the queries
Step 1: define the commercial query set
Start from the queries that matter commercially, not the ones easiest to win. List the questions a real buyer would ask an engine on the way to choosing this kind of provider. Twenty to forty queries is a workable set for most sites. Anchor them in real demand, drawn from sales calls, search data and the brand’s own service language.
Step 2: spread the set across intent
Distribute the queries across three intent levels: awareness questions that define the problem, consideration questions that compare options, and decision questions that name a category and location. A set weighted only to one level gives a distorted picture. The template below shows a balanced split.
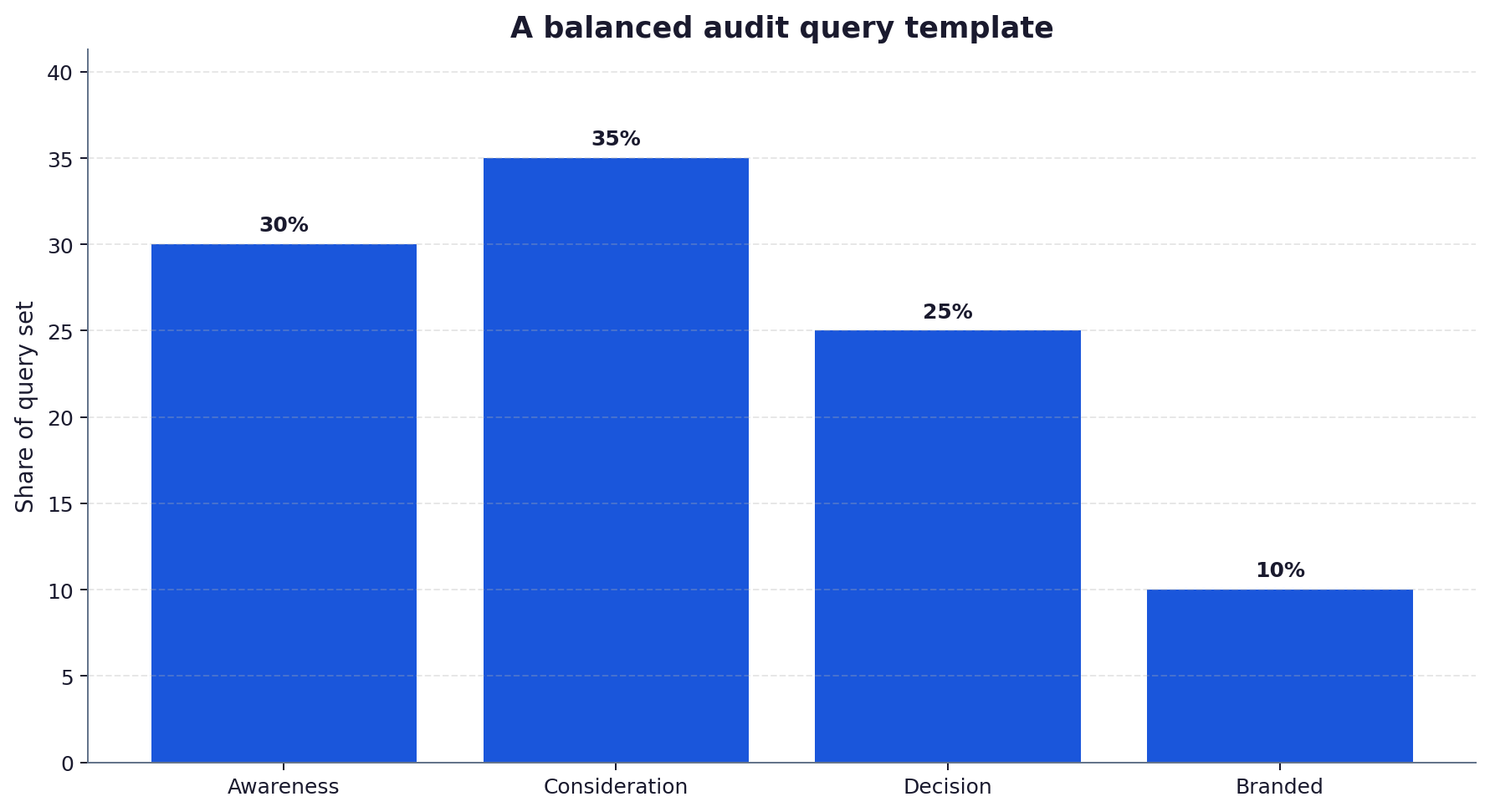
Step 3: fix the engines and the method
Decide which engines to audit, usually ChatGPT, Perplexity and Gemini, and fix the prompt wording, the sampling count and the definition of a citation before you collect anything. Writing the method down first is what makes the audit repeatable by someone else later.
Phase two: measure the current state
Step 4: sample each query several times per engine
Because AI answer sets shift between identical prompts, a single sample is noise. Ask each query three to five times per engine on each occasion and record the outcome every time. This smooths the per-call randomness so the rate you log reflects the brand’s real standing.
Step 5: log citations and recommendations separately
Record two things for every answer: whether the brand was cited as a source, and whether it was recommended in the body of the answer. These are different signals. A brand can be recommended without a citation, or cited without being recommended, and the gap between them tells you whether the problem is content or reputation.
Step 6: capture the competitive field
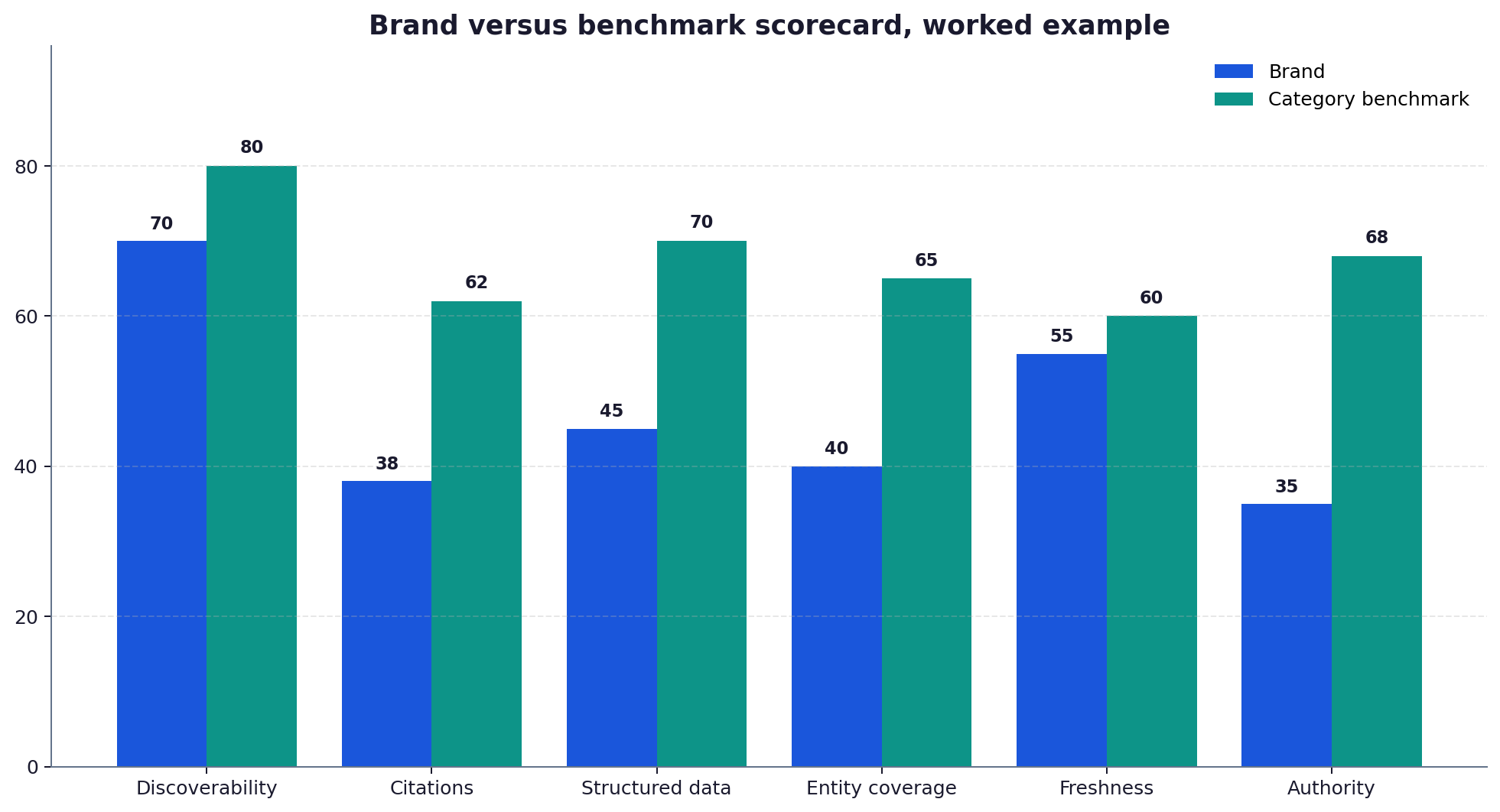
Log which competitors appear for the same queries. Visibility is relative: a 20 percent citation rate is strong in a quiet field and weak in a crowded one. Benchmarking against the brands that do appear turns a raw number into a meaningful position.
Phase three: score and prioritise
Step 7: score the six dimensions
Convert the observations into a score across six weighted dimensions: discoverability, whether the brand’s pages can be retrieved at all; citation presence, how often it is cited; structured data, the completeness of its schema; entity coverage, how well its people, services and credentials are defined; freshness, how current its key content is; and authority, the strength of its off-site standing. The weights reflect how much each dimension moves citations.
Step 8: roll up to a single visibility score
Combine the weighted dimensions into one figure out of a hundred. A single score is what makes audits comparable over time and across clients, and it gives a non-technical stakeholder something to track. Keep the dimension scores visible underneath, because the headline number tells you where you stand and the breakdown tells you why.
Step 9: produce a ranked fix list
Translate the lowest-scoring dimensions into specific, ordered actions: mark up these pages, define these entities, refresh this content, earn these mentions. Rank the list by expected citation impact against effort, so the brand works the highest-leverage fixes first rather than the easiest.
Step 10: set a re-audit cadence
An audit is a snapshot of a moving target. Re-run it on a fixed cadence, quarterly for most brands, using the identical query set and method, so the visibility score becomes a trend rather than a one-off reading. The cadence is what turns the audit from a sales artefact into a management instrument.
Why consistency is the whole point
The value of this method is not any single step, it is that the steps are fixed. When the query set, the engines, the sampling and the rubric stay constant, two analysts auditing the same site land close together, and the same site audited twice shows real movement rather than measurement drift. That reliability is what lets an agency stand behind a number, and it is the difference between an audit a client can act on and a screenshot they have to take on faith.
Frequently asked questions
How many queries should an AI visibility audit use?
Twenty to forty commercial queries is a workable set for most sites. The number matters less than the spread: the queries must cover awareness, consideration and decision intent so the audit reflects the whole buyer journey rather than one slice. Anchor them in real demand drawn from sales conversations, search data and the brand’s own service language. A larger set gives tighter estimates but costs more to sample, so size the set to the sampling effort you can sustain on each re-audit.
Why sample each query more than once?
Because AI answer sets change between identical prompts. Ask the same question twice and the cited sources often differ, so a single sample measures the noise as much as the brand’s real standing. Sampling each query three to five times per engine on each occasion and averaging the outcome smooths that randomness. Skipping repeated sampling is the most common reason two audits of the same site disagree, and it is the easiest mistake to avoid once you know to look for it.
What are the six scoring dimensions?
Discoverability, whether the brand’s pages can be retrieved at all; citation presence, how often it is cited in answers; structured data, the completeness of its schema markup; entity coverage, how well its people, services and credentials are defined; freshness, how current its key content is; and authority, the strength of its off-site standing. Each is weighted by how much it moves citations, with discoverability and citation presence usually carrying the most. The six combine into a single visibility score with the breakdown kept visible underneath.
How is this different from a normal SEO audit?
A traditional SEO audit checks rankings, crawlability and technical health against Google. An AI visibility audit measures whether a brand appears in generative answers across several engines, using the answer as the unit and citation share as the metric. The inputs overlap, structured data and content quality matter to both, but the question is different: not where do you rank, but do AI engines cite and recommend you. The two audits are complementary, and a brand serious about AI search needs the second alongside the first.
How often should the audit be repeated?
Quarterly suits most brands. AI answer sets drift, engines update how they weight sources, and the brand’s own content and competitors change, so a score that was accurate in January no longer is by April. Re-running the identical query set and method on a fixed cadence turns the visibility score into a trend you can manage rather than a single reading. The cadence is what makes the audit a management instrument instead of a one-off snapshot.
Can an agency really copy this methodology?
Yes. The structure, scope the queries, measure the current state, then score and prioritise, is openly reusable, and this article lays out all ten steps. What stays proprietary in any mature implementation is the exact dimension weights and the query bank tuned to a sector, both of which an agency develops with experience. The framework gives any team a defensible, repeatable starting point, and the consistency it enforces is worth more than any single clever weighting.
Sources and references
- GEO: Generative Engine Optimization. arXiv (Aggarwal et al.), 2024
- Citation Share Is the New Ranking Position: A KPI Framework. AiBoost, 2026
- Measuring brand presence across AI answers. Profound, 2026
- AI Overviews and citation patterns study. Ahrefs, 2026
- Organization, Article and FAQ types. Schema.org, 2026
- Knowledge Graph Search API. Google, 2026
Want the audit run for you first? A free AI visibility report applies this method to your own domain and shows where you stand across the major engines.
Change log
- 2026-06-11: Initial publication.