Traditional search engines organised the web by matching keywords in queries to keywords in pages. That approach worked when people typed a handful of terms into a box and sifted through lists of links. In a world of ai search optimisation, however, users increasingly ask full questions and expect direct answers. Generative platforms such as ChatGPT, Google’s Search Generative Experience (SGE) and Bing Copilot no longer just match words; they interpret ideas, connect concepts and craft responses using artificial intelligence. To appear in these answers, your content must be clear about what entities it mentions and how they relate to each other. Entity linking and semantic graphs provide the underlying structure that makes this possible.
This article demystifies how entity linking works, how large language models (LLMs) leverage knowledge graphs and semantic relationships, and why these techniques are essential for generative engine optimization. We will also explore practical steps to create entity‑friendly pages and show how well‑structured content can improve your visibility in generative results.
Why Entity Linking Matters in Generative Search
Search technology is moving from keywords to concepts. When users ask, “What’s the difference between lip fillers and dermal fillers?” or “How do I optimise my site for generative engines?”, an LLM must understand what “lip fillers” and “dermal fillers” are, whether the user is referring to the medical procedure, a cosmetic product or a legal question, and which information sources are trustworthy. It can no longer rely solely on matching a string of characters. Entity linking allows AI systems to map phrases in the question to specific, well‑defined entities. AI search engine optimisation therefore requires content creators to think in terms of entities and their relationships, not just keywords.
Understanding the retrieval pipeline for generative search helps explain this shift. When you ask an AI model a question, your text is tokenised and interpreted; relevant passages are retrieved from a knowledge base using vector embeddings; and the model synthesises an answer. If your page clearly links important words to real‑world entities, the retrieval system can recognise and fetch it. Without entity clarity, the AI might skip over your content or misinterpret it, hurting your chances of appearing in generative responses.
From Keywords to Concepts: The Semantic Shift in AI‑Driven Answers
SEO taught marketers to focus on keyword research, density and backlinks. When voice search and answer boxes emerged, Answer Engine Optimisation (AEO) emphasised concise Q&A formatting and conversation. Now generative engines require a deeper shift from words to meaning. How to optimise for AI search is no longer about guessing which term a user will type but about representing the entities they care about and how those entities relate to other concepts.
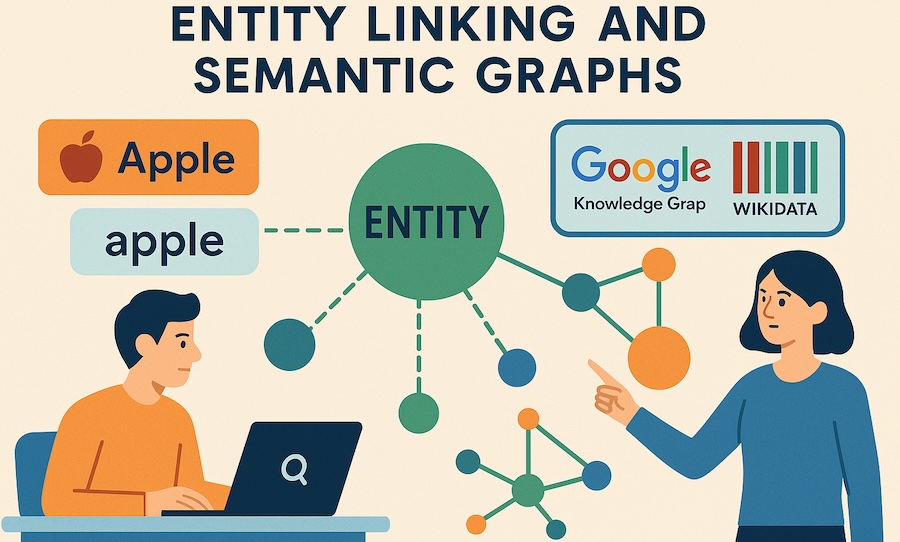
For example, a user might ask, “Who is Apple’s CEO?” If your article mentions “Apple” but doesn’t clarify whether you mean Apple Inc., Apple Records or the fruit, an AI may not confidently map your page to the question. Ambiguity reduces your chances of being retrieved and cited. When your content explicitly identifies “Apple Inc., the technology company headquartered in Cupertino, California, known for the iPhone,” it provides unambiguous semantic signals that generative engines can utilise. This is why entity linking and semantic graphs are integral to modern AI search.
What Is Entity Linking?
Entity linking (also called entity disambiguation) is the process of mapping mentions of words or phrases in text to specific, disambiguated entries in a knowledge base. A knowledge base, such as Wikipedia, Wikidata or a proprietary domain graph, contains structured information about entities – people, places, organisations, products, events and more – along with attributes and relationships between them.
When you read an article that mentions “Amazon,” humans usually know whether it refers to the e‑commerce company, the rainforest or the river based on context. Machines need help. Entity linking algorithms perform three main tasks:
- Identify candidate entities: Recognise mentions of potential entities in a text. Natural language processing (NLP) techniques – like Named Entity Recognition (NER) – identify proper nouns, products, dates and other entity types.
- Generate possible matches: For each mention, compile a list of possible entities in the knowledge base. For “Apple,” the system might consider “Apple Inc.,” “Apple Records,” and “apple (fruit).”
- Select the correct entity: Use contextual clues, semantic similarity, and prior probability to decide which entity the mention refers to. Advanced approaches use transformer‑based models to embed both the context and candidate entities into a vector space, enabling the system to select the closest match.
Once a word is linked to a specific entity, the AI can leverage structured data associated with that entity – such as its relationships, properties and metadata – to produce more accurate answers. This mapping not only reduces ambiguity but also connects your content to a larger semantic network.
Examples of Entity Linking
- “Apple” the company vs. “apple” the fruit: Without context, these two words are identical. Entity linking differentiates them based on surrounding text. A sentence like “Apple released the iPhone 15 Pro” will map “Apple” to the technology company; whereas “An apple a day keeps the doctor away” will map to the fruit.
- “Paris Hilton” vs. “Hilton Paris”: Entity linking differentiates between the celebrity “Paris Hilton” and a hotel in Paris. It also ensures that generative engines don’t inadvertently conflate unrelated entities.
- “Jaguar” car brand vs. “jaguar” animal: By linking to distinct entities, AI can provide relevant automotive specifications or wildlife facts depending on the question.
Such distinctions are critical for high‑precision AI answers and, by extension, for ai seo strategies that aim to increase brand authority in AI‑generated results.
How Generative Models Use Knowledge Graphs
Large language models are trained on vast amounts of unstructured text, but they also leverage structured knowledge graphs to improve accuracy and trustworthiness. A knowledge graph is a network of nodes (entities) and edges (relationships) that represent real‑world information in a machine‑readable format. Examples include Google’s Knowledge Graph, Microsoft’s Satori and open repositories like Wikidata. Domain‑specific graphs also exist for areas such as medicine, finance and law.
Linking User Queries to Nodes and Relationships
When you ask an AI, “What is hyaluronic acid used for in cosmetic procedures?”, the model uses entity recognition to identify “hyaluronic acid” as a chemical compound. It then retrieves related entities: “dermal fillers,” “lip augmentation,” and “aesthetic clinics.” Knowledge graphs encode relationships such as “hyaluronic acid is used in dermal fillers” or “dermal fillers are provided by aesthetic clinics.” By traversing these relationships, the AI can piece together a coherent answer that explains the role of hyaluronic acid in lip fillers and offers context about safety and clinics.
Knowledge graphs provide grounding and reduce hallucination. They also allow generative engines to surface trustworthy data about an entity’s attributes (location, history, market cap) or relationships (parent company, founder). When content creators align their pages with knowledge graph entries – for example, using schema markup to mark “Company” or “Person” – they make it easier for search engines to incorporate their information into generative responses.
Why Knowledge Graphs Provide Trust and Factual Grounding
Generative models sometimes produce plausible but incorrect statements, known as hallucinations. By anchoring responses in a knowledge graph, AI systems can cross‑reference statements with verified data. Structured sources help check facts, such as a CEO’s name or a medication’s primary use, and provide a base for reasoning over relationships. For businesses, being accurately represented in these graphs ensures that your brand information is conveyed correctly in AI‑generated answers.
Semantic Graphs in Generative Engines
A semantic graph is a representation of knowledge that emphasises meaning and relationships. Nodes represent entities (e.g., “lip filler,” “hyaluronic acid,” “aesthetic clinic”), and edges represent relationships (e.g., “contains,” “offered at,” “recommended for”). In generative engines, semantic graphs are used to infer connections between concepts, fill in gaps and answer complex questions.
What Does a Semantic Graph Look Like?
Imagine a graph where “lip filler” connects to “hyaluronic acid” with the relation “uses” and to “aesthetic clinic” with the relation “performed at.” Other edges might link “hyaluronic acid” to “safety” or “side effects.” When an AI receives a query, it maps the question to relevant nodes and explores neighbouring nodes to gather information. The model can then synthesise an answer that draws on multiple related concepts rather than relying on a single page.
How AI Uses Relationships to Determine Relevance
Relationships indicate context. If a page about lip fillers also links to general skincare advice, an AI might consider the connection less relevant than a page that explicitly links lip fillers to hyaluronic acid and aesthetic clinics. Semantic proximity, measured through vector embeddings, helps generative systems rank and select content for retrieval. Pages with clear relationships between entities therefore have a higher chance of inclusion in AI answers.
Examples: Connecting “Lip Filler” → “Hyaluronic Acid” → “Aesthetic Clinics”
Suppose someone asks, “What are lip fillers made of and where can I get them?” A generative model links “lip filler” to “hyaluronic acid” (composition) and “aesthetic clinic” (provider). If your content explicitly states that lip fillers usually contain hyaluronic acid and are offered at licensed clinics, the AI will consider it highly relevant. Your site becomes a candidate for inclusion in generative search results.
Entity Recognition in Practice
Entity recognition is the first step towards linking content to a knowledge graph. Modern NLP techniques – including rule‑based methods, statistical models and neural networks – identify entities in unstructured text. Here are key aspects of entity recognition in practice:
- Natural Language Processing Techniques: Named Entity Recognition (NER) labels tokens in text as “person,” “organisation,” “location,” “product,” etc. These labels can be refined into domain‑specific types like “chemical,” “disease” or “algorithm.” Entities can also span multiple words (“San Francisco,” “OpenAI”).
- Embeddings for Entity Mapping: Once entities are recognised, they are often converted into vector embeddings that capture semantic meaning. Embedding models such as Word2Vec, GloVe and transformer‑based sentence encoders represent each entity as a point in a high‑dimensional space. Similar concepts cluster together, making it easier to compare context and identify correct matches.
- Disambiguation and Citation: In AI answers, it’s not enough to mention an entity; the model must cite the correct sources. Disambiguation ensures that a mention like “Musk” maps to “Elon Musk” (the entrepreneur) and not to another individual with the same surname. For generative search, disambiguation reduces the risk of citing irrelevant or inaccurate information.
How Disambiguation Ensures Correct Citation of Sources
Imagine a blog post about “Mercury.” Without context, “Mercury” could refer to the planet, the element or the Roman god. If your post is about planetary science, disambiguation ties the mention to the astronomical entity “Mercury (planet).” Then, when a generative model answers “What is the distance of Mercury from the Sun?” it can reliably use your page as a source. Clear entity linking improves the precision of citations, increasing your chances of being cited.
How Entities Influence Citation Selection
Entity linking isn’t only about understanding; it’s also about ranking. Generative engines prefer content that:
- Clearly Defines Entities: Pages that unambiguously identify entities provide strong signals to AI. Using precise names, official titles and consistent terminology helps the retrieval system trust your content.
- Uses Consistent Names, Units and Terminology: If you refer to “generative engine optimisation” in one place and “GEO” in another, make sure to clarify that they mean the same thing. Inconsistent naming can confuse retrieval systems and weaken your semantic footprint. The same applies to units (“milligrams” vs. “mg”) and variations (“United States” vs. “USA”).
- Balances Detail with Brevity: Generative engines extract snippets from your content. Including concise, factual statements – ideally under 25 words – gives them ready‑made quotable sections. For example, “Hyaluronic acid is a natural substance used in dermal fillers to add volume to lips” is more likely to be cited than a long, meandering sentence.
Case Example: “ChatGPT SEO” vs. “Generative Engine Optimization (GEO)”
Suppose you run an ai seo consultant service and write about optimising content for ChatGPT. If you casually interchange “ChatGPT SEO,” “Generative Engine Optimisation,” “GEO” and “AI search,” the meaning may become ambiguous. To strengthen your presence in generative results, define your terms explicitly: “Generative Engine Optimization (GEO) is an advanced form of ai search engine optimisation focused on training large language models like ChatGPT to cite your content.” By linking each abbreviation to the underlying concept, you improve both human readability and machine interpretation.
Building Semantic Connections in Content
Creating entity‑friendly pages requires more than just adding definitions. You need to embed entities into a network of relationships that reflects how they exist in the real world. Here’s how to build semantic connections:
- Structure Pages Around Core Entities and Sub‑Entities: Choose a main topic (e.g., “hyaluronic acid”) and related sub‑entities (e.g., “dermal fillers,” “collagen,” “side effects”). Each section should focus on one entity and explain how it relates to the core. This structure helps both readers and AI understand the page’s organisation.
- Use Schema Markup to Reinforce Entity Identity: Implement schema.org types such as
Person,Organization,Product,FAQPage, orHowToin your HTML. Schema markup exposes your entities and their attributes in a machine‑readable format, guiding search engines and generative systems. For example, aProductschema for “Hyaluronic Acid Dermal Filler” can include properties like “brand,” “activeIngredient,” “medicalUse” and “manufacturer.” - Link Internally Between Pages to Form Content Clusters: Connect your articles on related topics with clear anchor text. If you have separate posts about lip fillers, dermal fillers and hyaluronic acid, cross‑link them using descriptive phrases like “learn more about dermal fillers here.” These internal links create a web of connections that mirrors the semantic graph, aiding retrieval systems.
Practical Tutorial: Creating an Entity‑Friendly Page
Let’s walk through a step‑by‑step process for crafting a page optimised for entity linking and generative search. This guide combines best practices from AEO and GEO and will be particularly valuable if you’re wondering how to optimise for ai search.
Step 1: Identify Main and Supporting Entities
Start by defining the core subject of your page. For example, if your article is about “lip fillers,” list related entities such as “hyaluronic acid,” “collagen,” “aesthetic clinics,” “FDA approval” and “lip augmentation.” Decide which entity is the star of the page and which are supporting.
Step 2: Build Relationships with Context and Examples
In each section, explain how the supporting entity relates to the core entity. For “hyaluronic acid,” describe its chemical properties, how it is used in fillers and why it’s preferred over collagen for temporary augmentation. Use simple sentences and avoid jargon. Provide examples and compare alternatives. This narrative builds a semantic graph that AI models can traverse.
Step 3: Add Structured Data (Schema) and Consistent Terminology
Use schema markup to formalise your entities. A FAQPage schema could outline common questions like “How long do lip fillers last?” with answers. Include the same official names of entities in your schema and body copy. If you mention both “lip filler” and “lip augmentation,” make sure you explain that lip augmentation is the procedure and lip filler is the product. This consistency strengthens entity linking.
Step 4: Use FAQs to Capture Natural Language Queries
Incorporate a section of frequently asked questions using simple, conversational language. Each question should mirror how a user might ask it aloud: “Are lip fillers safe?” or “Where can I get lip fillers?” Provide concise answers (under 25 words) that still include the relevant entity names. This format aligns with both AEO and GEO principles and improves your chances of appearing in voice search and AI snippets.
Why Entity Linking Boosts GEO Success
Entity linking strengthens your presence in generative search for several reasons:
- Alignment with Retrieval Systems: AI models use embeddings and knowledge graphs to find relevant content. Well‑linked entities increase the semantic similarity between your page and the user’s query, making it more likely to appear in the candidate set.
- Higher Trust and Citation Likelihood: Generative engines prioritise sources that are authoritative, factual and clearly structured. When your content explicitly defines entities and relationships, it conveys expertise and trustworthiness. This improves your chances of being cited and reduces the risk of misattribution.
- Reduced Risk of Misrepresentation: Ambiguous or inconsistent entity references can cause AI to misquote or misinterpret your information. Strong entity linking reduces this risk and ensures your brand is represented accurately in generative responses.
- Future‑Proofing for Multi‑Modal Search: As AI evolves, search will span text, voice, images and video. Entity linking and semantic structures remain relevant across modalities. For example, an AI might recognise the entity “lip filler” in a video transcript, map it to a knowledge graph and search for related articles. By investing in semantic clarity now, you prepare your content for emerging forms of AI discovery.
Conclusion
Generative search represents a profound shift from keyword matching to meaning‑driven answers. Entity linking and semantic graphs form the hidden scaffolding that enables LLMs to understand and respond to user queries. For businesses, mastering these techniques is essential to thrive in the era of generative engines. By clearly defining entities, building relationships between them and structuring content for machine readability, you position your pages as trustworthy sources for AI answers.
Entity clarity equals credibility. Investing in semantic structures today ensures that your expertise is recognised tomorrow, whether a user asks a smart speaker, types a question into an AI search engine, or engages with a chatbot. As ai search engine optimisation continues to evolve, focusing on entities and their connections will keep you visible and relevant in generative search results.
Want to know whether ChatGPT, Perplexity, or Google AI Overviews mention your firm? Run a free first-party visibility audit on your domain in under a minute and see exactly which queries cite you and which do not.