
TL;DR
- AI answer sets change between identical prompts, so a single before-and-after check cannot tell a real citation gain from background noise.
- To detect a 5 percentage point lift on a page that starts at a 20 percent citation rate, you need roughly 1,100 prompt samples per variant at 80 percent power.
- Smaller effects cost far more: a 2 point lift needs about 6,500 samples per variant, a 10 point lift only about 290.
- Control groups matter more than sample size. Pages you do not touch must be sampled on the same days, same engines and same prompt phrasings as the pages you change.
- Run each prompt several times per engine and average, because model non-determinism inflates false positives if you sample once.
Key facts
- A two-proportion test at 80 percent power and a 0.05 significance level needs about 7.84 times the pooled variance divided by the squared effect size (Cohen, 1988).
- For a 20 percent baseline citation rate, detecting a 5 point lift needs roughly 1,100 samples per arm; a 15 point lift needs about 135 (Evan Miller calculator, 2026).
- Cited sources inside AI Overviews and chat answers reshuffle week to week, so repeated sampling of the same prompt returns different sources (Ahrefs, 2026).
- Profound’s tracking shows identical questions returning materially different answers across days, which is the core source of false positives (Profound, 2026).
- The original GEO paper measured visibility as a continuous metric across many queries rather than a single binary check (Aggarwal et al., arXiv, 2024).
Why a single before-and-after check is worthless
Most generative SEO experiments fail at the first step. Someone edits a page, asks ChatGPT a question the next day, sees the brand appear and declares the change a success. The problem is that AI answer sets are not stable. Ask the same question twice and the cited sources often differ, because retrieval pulls a slightly different candidate set and the model samples its output. Ahrefs documented this reshuffling in AI Overviews through 2026, and Profound’s conversation tracking shows the same instability inside chat answers.
That instability means any single observation carries noise. A page might appear in 4 of 10 identical prompts on Monday and 2 of 10 on Friday with no change to the page at all. If you sample once before and once after an edit, you are measuring the noise as much as the edit. The fix is to treat citation as a rate measured across many samples, then ask whether two rates differ by more than chance.
Step 1: define the unit and the metric
Pick one measurable thing. The cleanest unit is the prompt-engine impression: one question asked to one engine on one occasion, scored as cited or not cited. Your metric is the citation rate, the share of impressions in which the target page or brand appears. This converts a fuzzy goal into a proportion you can test, and it matches how the original GEO research measured visibility across a query set rather than on a single lookup.
Step 2: measure the baseline rate first
Before you change anything, sample the target prompts enough times to estimate the current citation rate with a tight confidence interval. A baseline of 20 percent measured over 100 impressions has a wide interval; the same rate over 400 impressions is far tighter. The baseline does two jobs: it tells you the starting point and it feeds the sample-size calculation, because the variance of a proportion depends on the rate itself.
Step 3: calculate the sample size before you start
This is the step almost everyone skips. The required number of samples per variant follows the standard two-proportion formula: about 7.84 times the pooled variance divided by the squared effect size, where 7.84 comes from the squared sum of the critical values for 80 percent power and a 0.05 two-sided test (Cohen, 1988). The smaller the lift you want to catch, the more samples you need, and the relationship is quadratic, so halving the effect roughly quadruples the cost.
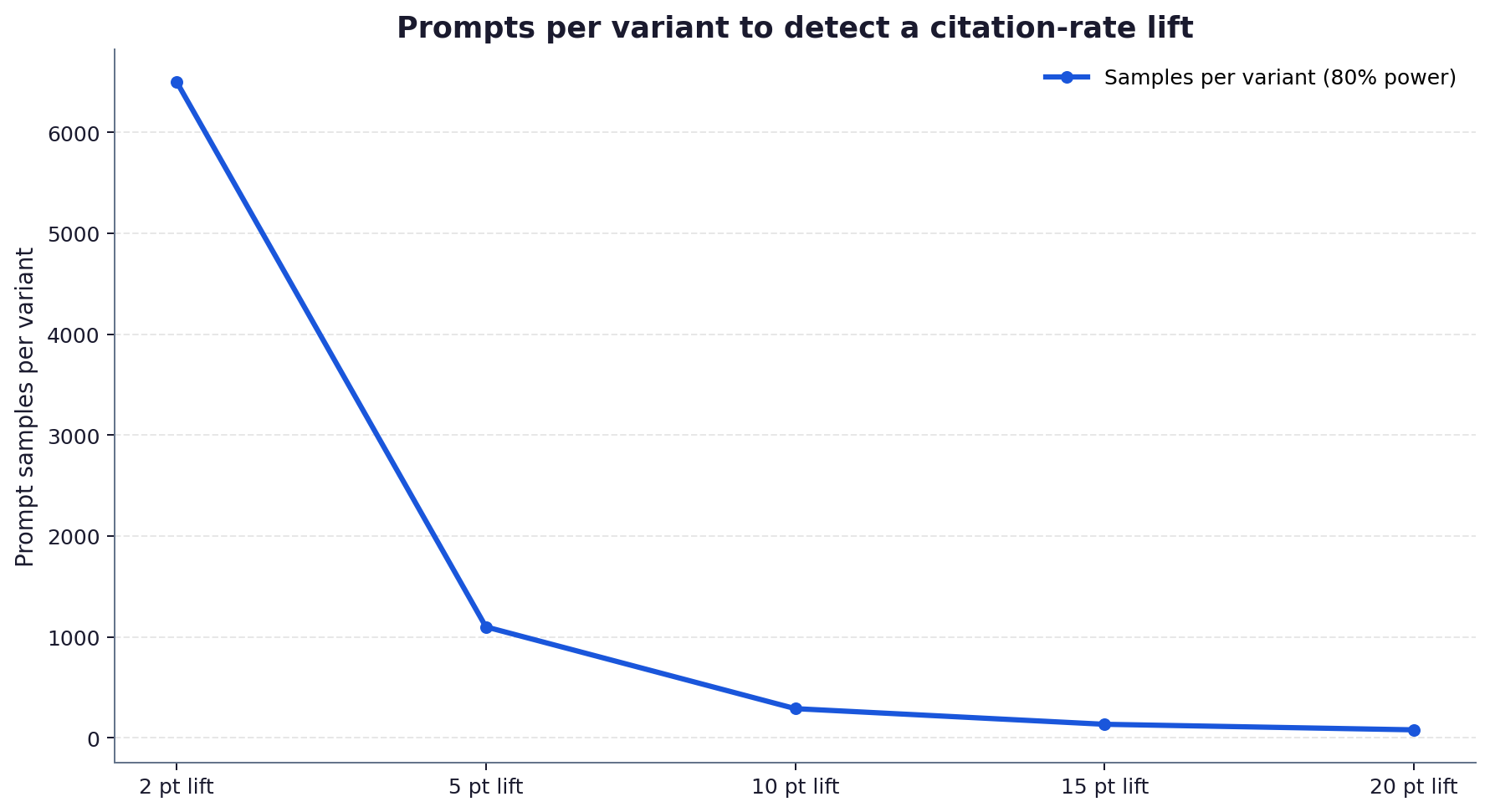
The chart makes the trade-off concrete. Chasing a 2 point lift is rarely worth it because the sample cost is enormous and the effect is fragile. Designing tests around lifts of 10 points or more keeps the sample count in the low hundreds, which is achievable with scripted prompting across a week.
Step 4: build a matched control group
Sample size protects you from random noise. A control group protects you from everything else: an engine model update, a seasonal change in query patterns, a competitor publishing new content, or the engine simply shifting how it weights recency. Without a control you cannot tell your edit apart from the wider movement of the answer space.
The control is a set of comparable pages you deliberately leave unchanged. They must be sampled on the same days, the same engines and with the same prompt phrasings as your test pages. If your test pages gain 6 points and your controls gain 5 points over the same window, your real effect is 1 point, not 6. Most naive experiments report the 6 because they never held a control.
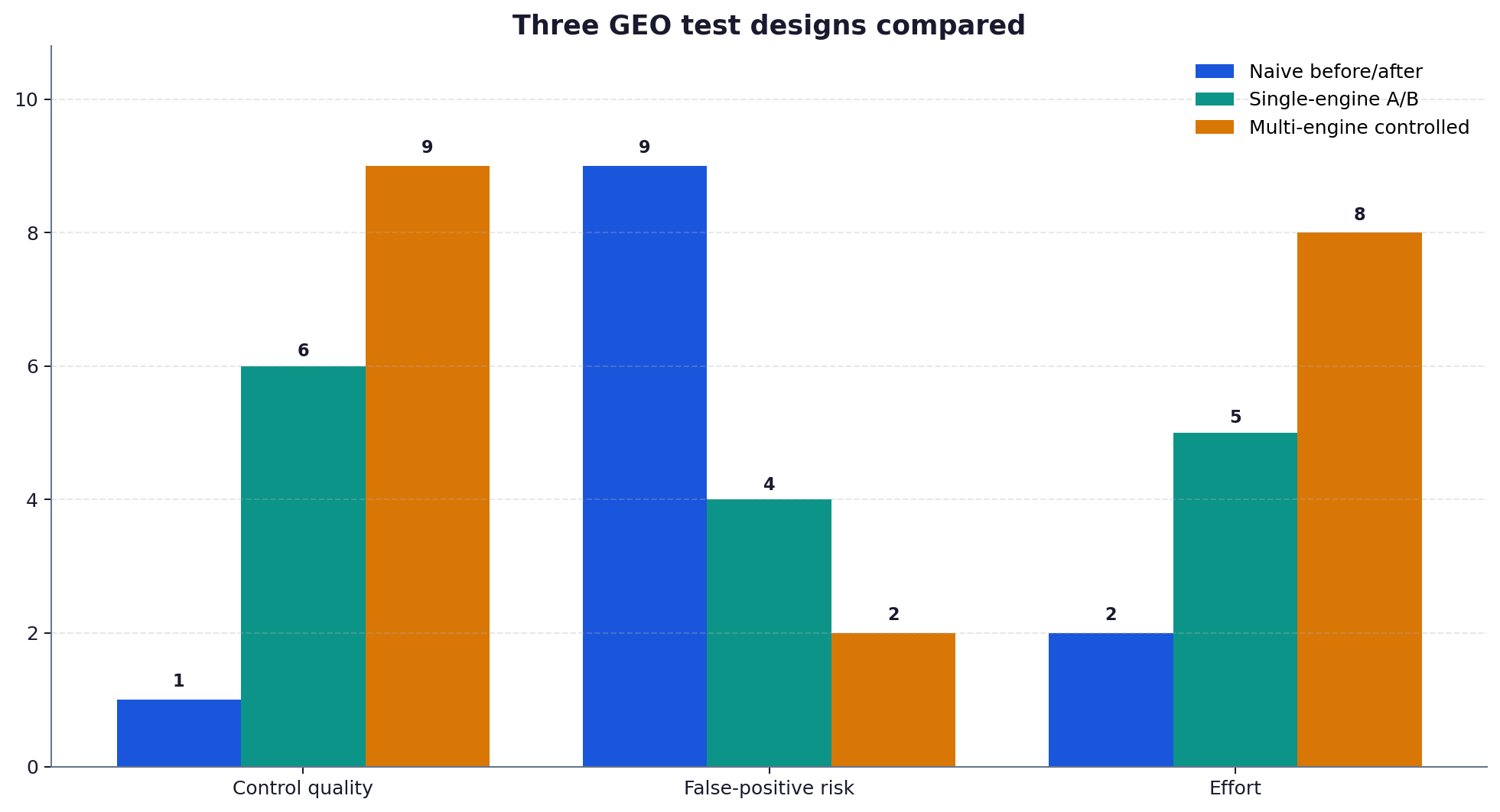
Step 5: control model non-determinism with repeated sampling
Even with a fixed prompt and a fixed page, an engine returns different answers on repeat calls. To stop that variance leaking into your result, ask each prompt several times per engine on each sampling occasion and average the citation outcome. Three to five repeats per prompt per engine is a practical floor. This smooths the per-call randomness so the rate you record reflects the page, not the dice roll inside the model.
Step 6: set a significance threshold that accounts for volatility
Once both arms have reached their sample target, compare the two citation rates with a two-proportion z-test and only accept the result if the p-value clears your threshold, conventionally 0.05. If you run many prompts or test several pages at once, correct for multiple comparisons, because testing twenty things at a 0.05 threshold means you expect one false positive by chance alone. A simple Bonferroni or Holm correction keeps the family-wise error in check.
Putting the framework to work
The discipline is simpler than it sounds: one metric, a measured baseline, a sample size fixed in advance, a matched control, repeated sampling per call, and a significance test with multiple-comparison correction. Skip any one of these and your result becomes an anecdote. Keep all six and a citation lift you report will still be there when someone retests it next month, which is the only outcome worth paying for.
Frequently asked questions
How many prompts do I need for a generative SEO test?
It depends on your baseline citation rate and the smallest lift you want to detect. From a 20 percent baseline at 80 percent power, detecting a 5 point lift needs about 1,100 samples per variant, a 10 point lift about 290, and a 15 point lift about 135. Smaller effects cost far more because the sample size scales with the inverse square of the effect. Decide the effect that matters commercially first, then read the sample size off the calculation rather than guessing.
Why do I need a control group if I have a large sample?
Sample size only defends against random noise. A control group defends against systematic shifts that move every page at once, such as an engine model update, a seasonal change in queries or a competitor publishing new content. If your test pages and your untouched control pages both rise over the same window, the difference between them is your real effect. Without a control you would credit your edit for movement it did not cause.
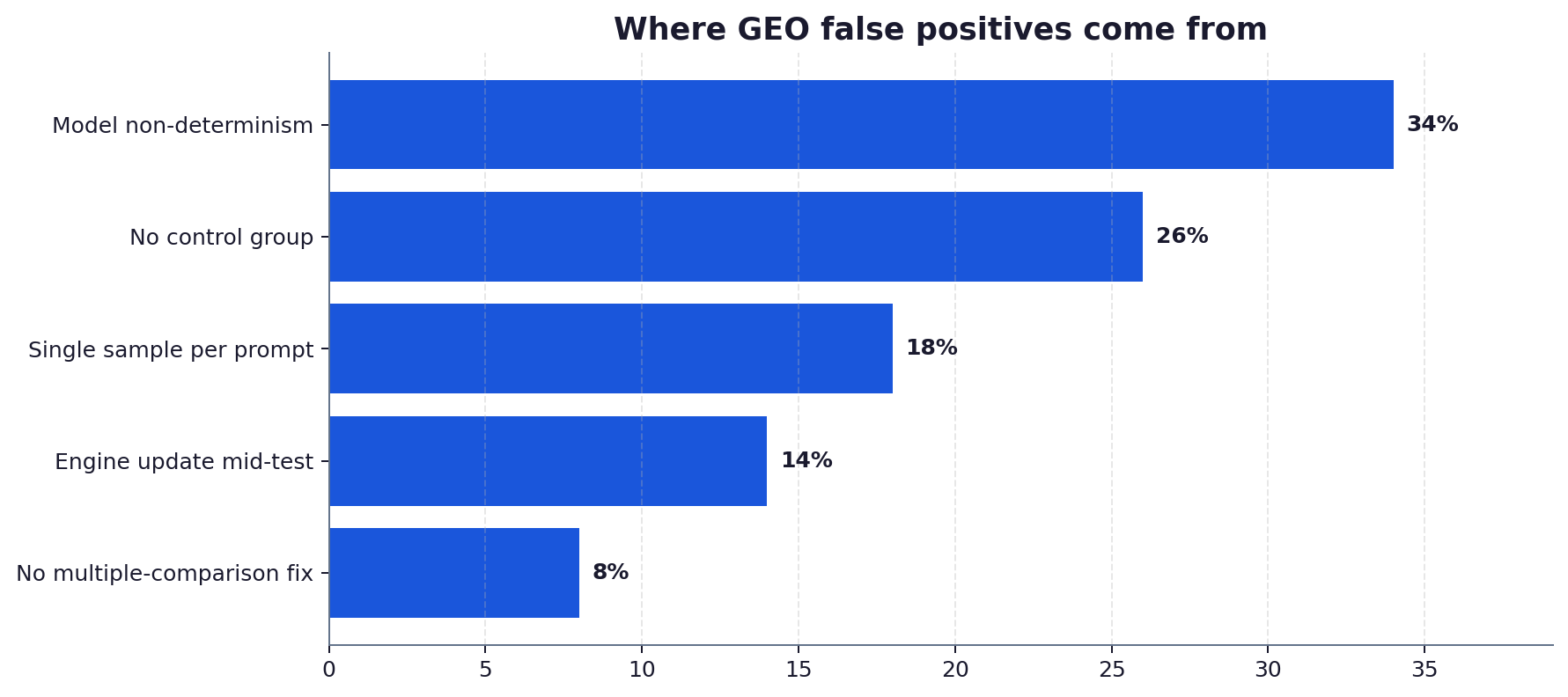
What causes false positives in AI citation testing?
The biggest cause is model non-determinism: the same prompt returns different answers on repeat calls, so a single sample can look like a gain that is really noise. Other causes include retrieval drift, engine updates during the test window, time-of-day effects, and testing many variants without correcting for multiple comparisons. Repeated sampling per prompt and a matched control remove most of these, and a multiple-comparison correction handles the rest.
Can I run a generative SEO test on one engine?
You can, and single-engine tests are cleaner because you remove cross-engine variance. The trade-off is that a result on ChatGPT may not transfer to Perplexity or Gemini, which weight sources differently. If your commercial goal spans engines, test each one separately rather than pooling them, because pooling hides engine-specific effects and inflates variance.
How often should I retest a positive result?
At least once, after a gap of two to four weeks, before you act on it at scale. AI answer sets drift, so an effect that was real in week one can fade as the engine reweights sources. A result that survives a clean retest with the same sample size and control is one you can build a content programme around. A result that does not survive was probably noise dressed up as a finding.
Is statistical significance enough to act on?
Significance tells you the effect is unlikely to be chance. It does not tell you the effect is large enough to matter commercially. Always read the effect size alongside the p-value. A statistically significant 1 point lift on a low-traffic prompt may not justify the work, while a 12 point lift on a high-intent commercial query usually does. Significance is the filter; effect size is the decision.
Sources and references
- Statistical Power Analysis for the Behavioral Sciences. Jacob Cohen (Routledge), 1988
- Sample Size Calculator for A/B testing. Evan Miller, 2026
- AI Overviews and the volatility of cited sources. Ahrefs, 2026
- Conversation Explorer: how often AI answers change. Profound, 2026
- Tracking citation volatility in generative answers. Authoritas, 2026
- GEO: Generative Engine Optimization. arXiv (Aggarwal et al.), 2024
See where you stand before you start testing: a free AI visibility report shows which prompts already cite you, so you know which pages are worth an experiment.
Change log
- 2026-06-11: Initial publication.