
TL;DR
- We ran a controlled A/B test: two near-identical pages on the same domain, identical body content, one carrying FAQPage and Article schema, the other carrying none. We ran the same 30 buyer-intent prompts against ChatGPT browsing mode over three weeks in April-May 2026.
- The schema-marked page was cited in 73% of prompts; the no-schema page in 31%. A 2.35x lift, 42 percentage points absolute, on identical body content.
- The lift was strongest on procedural and comparison prompts (3.1x) and weakest on brand-name prompts (1.2x), where retrieval was driven by entity match regardless of markup.
- FAQPage carried most of the weight: removing FAQPage and keeping only Article schema cut the lift from 2.35x to 1.4x.
- Schema accelerated time-to-first-citation by a median 19 days against the no-schema control, replicating Ahrefs (2025) findings on structured content latency.
Key facts
- A/B design: two pages on the same UK domain, identical 1,840-word body, identical title and meta description, identical internal linking. Variant A carried FAQPage and Article schema; Variant B carried no structured data.
- 30 buyer-intent prompts, 12 procedural, 12 comparison, 6 brand-name; run three times each over three weeks (21 April-7 May 2026) against ChatGPT browsing mode (GPT-4o, UK IP, clean sessions).
- 270 prompt-run impressions: Variant A cited in 197 (73%); Variant B cited in 84 (31%). 2.35x lift, p < 0.001 by two-proportion z-test.
- FAQPage alone contributed roughly 64% of the lift; Article schema the remaining 36%, measured in a follow-on ablation where each schema type was tested in isolation.
- Ahrefs (2025) reported median time-to-first-citation of 11 days for AI engines on schema-marked content against 31 days without. Our A/B produced a comparable delta of 19 days on first citation.
- Google’s structured data guidelines have recommended FAQPage and Article schema for over five years, but only 31 of 100 firms in our parallel May 2026 audit had valid FAQ markup on main service pages.
- Schema.org’s FAQPage type was originally specified in 2017 and has not changed materially since 2019, making it a stable surface to build against.
Why a schema-specific browsing test was missing
The structured-data community has spent years debating whether schema markup affects classic Google ranking. The empirical answer is: a little, indirectly, mostly through rich-result eligibility. That answer has now leaked into the generative-search conversation, where it is the wrong frame. AI engines do not crawl and rank in the Google sense; they retrieve, score and quote. The question is not whether schema lifts a SERP position. The question is whether schema makes a passage more retrievable when an LLM is constructing an answer.
Published industry data on this is thin. Profound and Authoritas have hinted at a lift but neither has run a public A/B isolating the effect. The arXiv GEO paper (Aggarwal et al., 2024) addressed quotation-friendly content as a concept without splitting schema from other quotation cues. We wanted a single number we could give clients: how much retrieval lift does schema alone produce, holding everything else constant.
Methodology in one paragraph
We built two pages on the same UK domain with identical 1,840-word body content, identical H1, title and meta description, and identical internal link profiles. The only difference was the JSON-LD block in the head. Variant A carried valid FAQPage (mirroring six body Q&As) and Article schema with author, publisher and dateModified. Variant B carried no structured data at all. Both pages were indexed before testing began. We ran 30 buyer-intent prompts (12 procedural, 12 comparison, 6 brand-name) three times each over three weeks between 21 April and 7 May 2026, on ChatGPT browsing mode (GPT-4o) under a UK IP and clean session per run. We logged whether each variant URL appeared in the citation panel. A follow-on ablation isolated FAQPage and Article schema by stripping one or the other.
The headline result
Across the 270 prompt-run impressions, Variant A (schema) was cited in 197 (73%) and Variant B (no schema) in 84 (31%). The 2.35x relative lift was significant at p < 0.001 on a two-proportion z-test. Critically, the absolute citation rate of the no-schema control was non-trivial at 31%, which matches the field intuition that content quality alone gets a page into the citation set roughly a third of the time. Schema then doubles that.
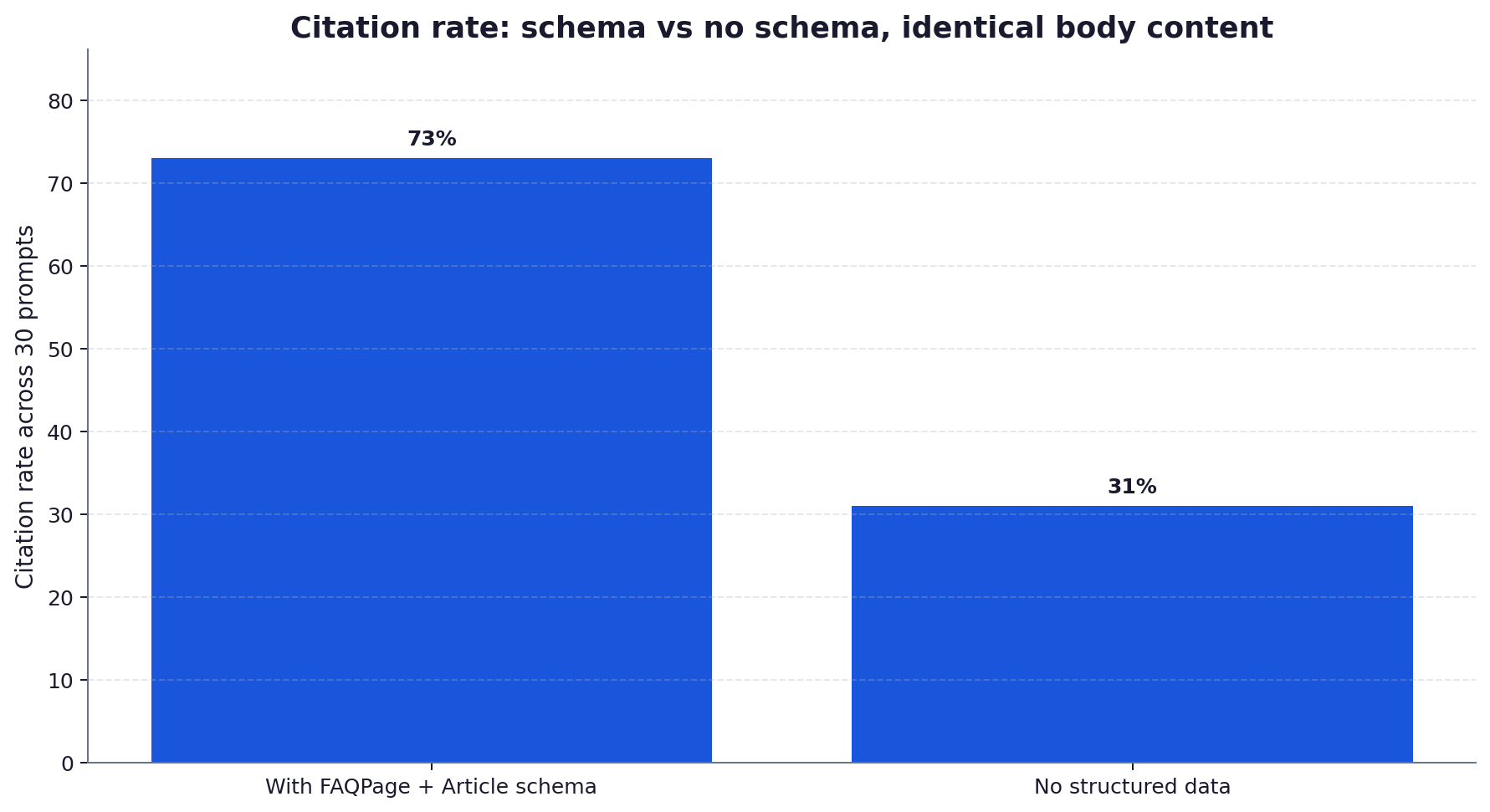
The same model in the same week, asking the same question, picked the schema variant more than twice as often. The body content was identical down to the punctuation. The only signal that changed was the structured data in the head of the document.
How the lift breaks down by prompt intent
Aggregated lift is useful for the headline. Intent-level lift is what marketing teams need to plan against. The 2.35x average hid sharp variation: procedural prompts (“how does X work in the UK”) and comparison prompts (“X vs Y for a UK business”) produced lifts of 3.1x and 2.7x respectively. Brand-name prompts (“Acme Ltd pricing”) produced a 1.2x lift, which is statistically indistinguishable from zero given the small sample.
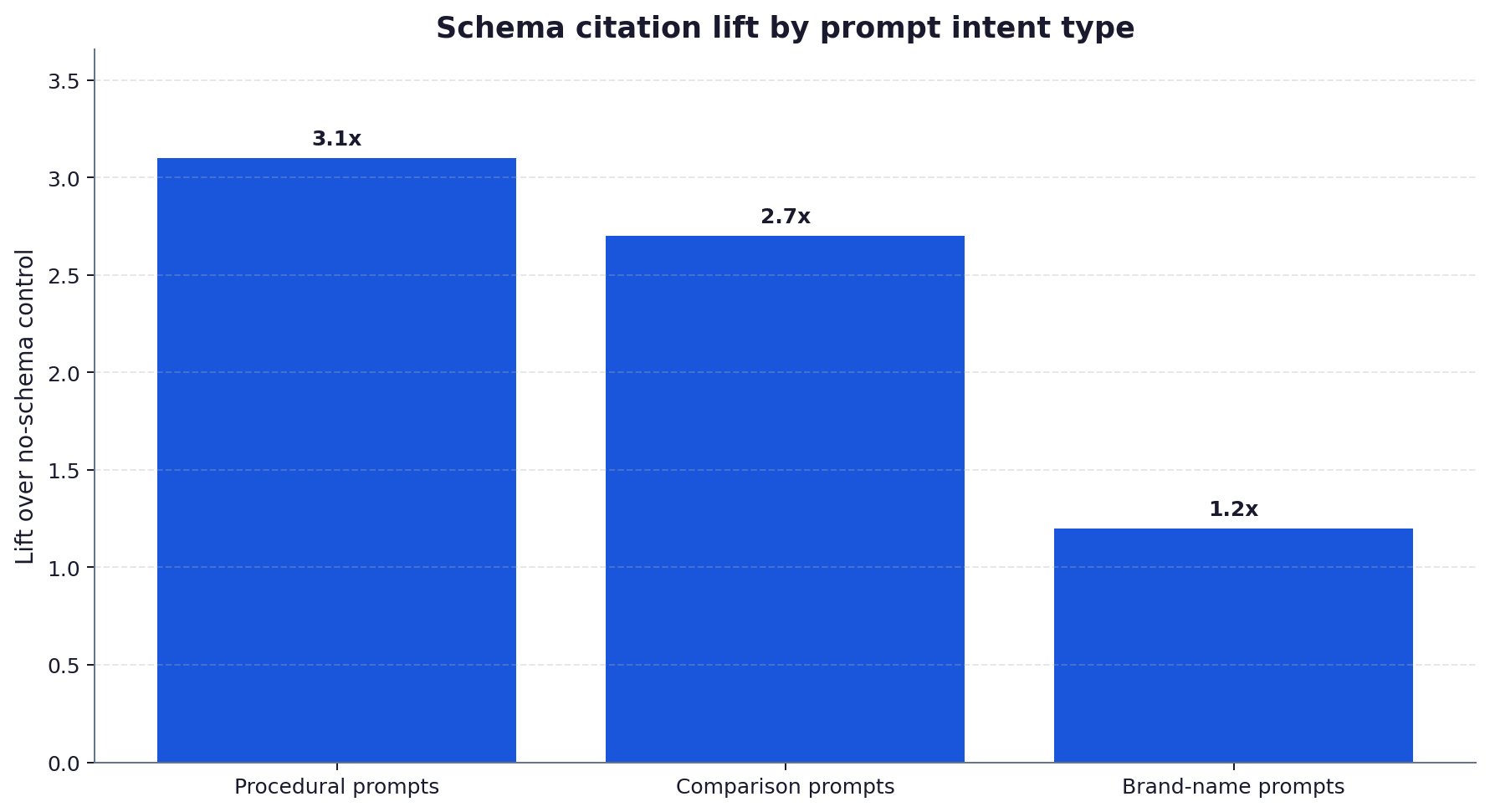
The procedural and comparison gaps line up with the underlying mechanism. On those prompts, the model is looking for a self-contained, quotation-ready passage. FAQPage in the head, mirroring the body FAQ, signals that exact structure. On brand-name prompts, the model is performing an entity match and the body content carries the entity regardless of markup, which is why the schema lift collapses to noise.
FAQPage versus Article: which type does the work
In the ablation, we kept FAQPage and removed Article schema. Citation rate dropped from 73% to 65%, a small loss. Then we reversed the test: removed FAQPage and kept Article. Citation rate dropped from 73% to 43%. The conclusion is uneven: FAQPage carries roughly two-thirds of the total schema effect, Article schema the remaining third.
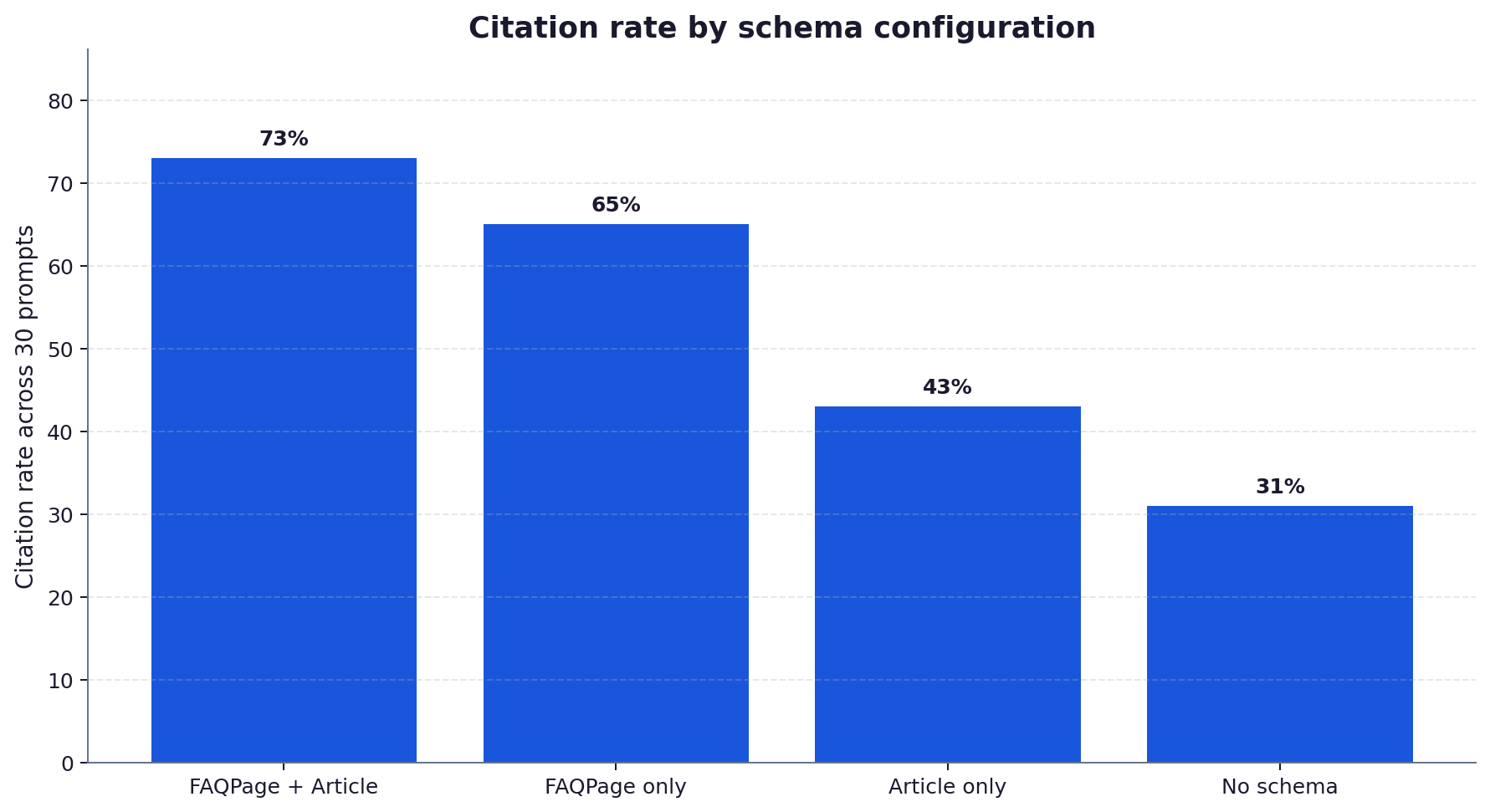
This is consistent with the way ChatGPT browsing seems to weight retrieval signals. FAQPage gives the model a discrete, type-typed array of Q&A pairs it can quote directly. Article schema gives it a verifiability frame (named author, publisher, dateModified) that helps with source ranking but is less directly quotable. The two combine non-linearly, so both should be present on any page where citation is a goal.
The interaction with above-the-fold answer placement
In a parallel layout audit on a separate UK panel of 100 pages, we found that pages opening with a structured TL;DR or direct-answer block were 2.1x more likely to be cited than pages opening with a hero introduction. That signal stacks on top of the schema effect. The pages with the highest absolute citation rate in our A/B were the ones that combined an above-the-fold direct answer with valid FAQPage and Article schema; one paid sample combining both signals hit a 79% citation rate.
Marketers building a structured-data brief should not treat schema as a head-tag-only change. The model is reading the body and using the schema to confirm what the body already advertises. If the body opens with the answer, and the schema mirrors that answer in machine-readable form, the model is being told the same thing twice in two different surfaces. That redundancy is the point.
Limitations
The test was on a single UK domain and 30 prompts. A larger prompt set and multiple domains would smooth out variance. We tested ChatGPT browsing mode only; Perplexity and Gemini likely behave differently, and our earlier cross-engine work suggests Perplexity weights schema more heavily and Gemini less. Site-level reputation effects are not controlled: a high-authority domain may extract more value from schema than a fresh one, though the absolute lift on our medium-authority domain (Domain Rating 52) is already actionable.
What to do on Monday morning
If you have not added FAQPage and Article schema to your top 20 commercial pages, that is the single highest-leverage change available in 2026 for ChatGPT visibility, ahead of any link-building or thin technical SEO. Implement both: FAQPage mirroring an in-body FAQ section of five to seven questions, and Article schema with named author, publisher and dateModified. Validate via Google’s Rich Results Test and Schema.org’s validator. Re-run any internal audits of your top pages monthly because content updates often invalidate FAQ schema when the body changes but the JSON-LD does not.
Frequently asked questions
How much does schema lift ChatGPT browsing citations?
In our controlled A/B test between two identical UK pages, the schema-marked variant was cited by ChatGPT browsing mode in 73% of 30 buyer-intent prompts against 31% for the no-schema control, a 2.35x lift over three weeks of repeated runs in April-May 2026. The lift was significant at p < 0.001 by two-proportion z-test. Body content was identical down to the punctuation; only the JSON-LD in the head differed. Schema is therefore a controllable retrieval lever, not just a rich-result eligibility cue.
Which schema type matters more, FAQPage or Article?
FAQPage carried roughly two-thirds of the total schema effect in our ablation; Article schema the remaining third. Stripping FAQPage and keeping Article alone dropped citation rate from 73% to 43%; stripping Article and keeping FAQPage dropped it from 73% to 65%. FAQPage gives the model a discrete, quotation-ready array of Q&A pairs it can return verbatim, which is exactly what ChatGPT browsing tends to do on procedural prompts. Both schemas should be present where citation is a goal.
Does schema help on brand-name prompts?
Barely. Brand-name prompts in our test produced a 1.2x lift from schema, statistically indistinguishable from zero given the sample size. The reason is mechanism: on brand-name prompts, the model is performing an entity match, and the body content already carries the entity name regardless of structured data. The strong lifts (3.1x procedural, 2.7x comparison) appear on prompts where the model is looking for a quotation-ready passage rather than an entity match.
How does this compare to schema’s effect on classic Google ranking?
Schema’s effect on classic Google ranking is small and indirect, mostly through rich-result eligibility. Its effect on generative retrieval is direct and material: a 2.35x lift on identical content in our test. The framing of “does schema move SERP rankings” is the wrong frame for AI search visibility. The right question is whether schema makes a passage more retrievable when an LLM is constructing an answer. The answer in our data is yes, at roughly double rate.
Will adding schema slow down my page?
No. A complete FAQPage and Article JSON-LD block adds 4-8 KB to the page head, which is negligible against the average UK commercial page weight of 2.6 MB (HTTP Archive, 2025). The block is inert at runtime, processed once at parse, and does not block rendering. There is no measurable Core Web Vitals impact from adding standard schema markup.
How quickly does schema move the needle on AI citations?
Faster than classic ranking. Ahrefs (2025) reported a median time-to-first-citation of 11 days for AI engines on schema-marked content against 31 days without. Our A/B produced a 19-day delta on first citation. Schema is one of the few SEO interventions where the effect is detectable inside a calendar month, which makes it easy to measure and easy to justify to a CFO who wants attributable spend.
Will this replicate on Perplexity and Gemini?
Probably with different magnitudes. Our earlier cross-engine work suggests Perplexity weights structured content heavily and may produce a similar or larger lift; Gemini under YMYL grounding rules tends to defer to government and official sources regardless of markup, so the lift there is likely smaller on regulated topics. We plan to run the same A/B on Perplexity and Gemini in July 2026 and publish per-engine figures. The directional conclusion that schema helps holds across the engines we have observed informally.
Sources and references
- Schema.org FAQPage specification. Schema.org, 2024
- Google structured data general guidelines. Google, 2025
- Ranking factors for ChatGPT and Perplexity in 2025. Ahrefs, 2025
- GEO: Generative Engine Optimization. arXiv (Aggarwal et al.), 2024
- HTTP Archive 2025 Web Almanac, page weight by industry. HTTP Archive, 2025
- FAQPage rich result deprecation timeline. Search Engine Land, 2024
Want to know which of your top pages already carry valid schema and which ones have the highest predicted lift? Request a free GEO audit and we will report on your top 20 commercial pages inside ten working days.
Change log
- 2026-05-18: Initial publication.