
TL;DR
- AI engines reason over entities, the people, places, services and concepts behind your words, not the keywords themselves (Google, 2012).
- An entity-gap audit compares the entities your content defines against a reference snapshot from Wikidata or the Google Knowledge Graph, then lists what is missing.
- The seven steps are: pick a reference graph, extract your entities, map to the graph, score coverage by type, find the gaps, prioritise by commercial value, and fix with schema and content.
- The most common gaps are key people, credentials and services treated as plain text rather than defined, linked entities.
- Closing entity gaps gives engines the structured facts they need to cite you confidently, which is the precondition for appearing in answers.
Key facts
- Google reframed search around entities, things not strings, in 2012, and AI answers inherit that model (Google, 2012).
- The Google Knowledge Graph Search API and Wikidata both expose machine-readable entity records you can audit against (Google, 2026; Wikidata, 2026).
- Schema.org defines the Organization, Person and Service types that let you declare an entity and its relationships explicitly (Schema.org, 2026).
- The GEO research framed visibility as a function of how clearly content supports retrieval and attribution, not raw keyword density (Aggarwal et al., arXiv, 2024).
- Structured data measurably shifts which pages AI surfaces choose to cite (Ahrefs, 2026).
Why entities, not keywords, decide AI citations
When an engine answers a question, it is not matching strings. It is resolving the question to a set of entities, retrieving content that defines those entities, and attributing claims back to sources it trusts. Google made this shift explicit in 2012 with the Knowledge Graph and the slogan things not strings. AI answer engines extend the same logic: they prefer content where the entities are clearly defined, consistently named and linked to known references.
That is why two pages targeting the same keyword can have wildly different AI visibility. The page that defines its organisation, its people, its services and its locations as explicit entities gives the engine clean facts to lift. The page that buries the same information in prose forces the engine to guess, and engines cite what they can verify, not what they have to infer.
Step 1: choose a reference knowledge graph
You need something to audit against. The two practical choices are Wikidata, which is open and queryable, and the Google Knowledge Graph, reachable through its Search API. Wikidata is better for understanding how an entity relates to others; the Google graph is better for seeing what Google already associates with your brand. Most audits use both: Wikidata for the entity model, Google for the existing brand record.
Step 2: extract the entities your content already defines
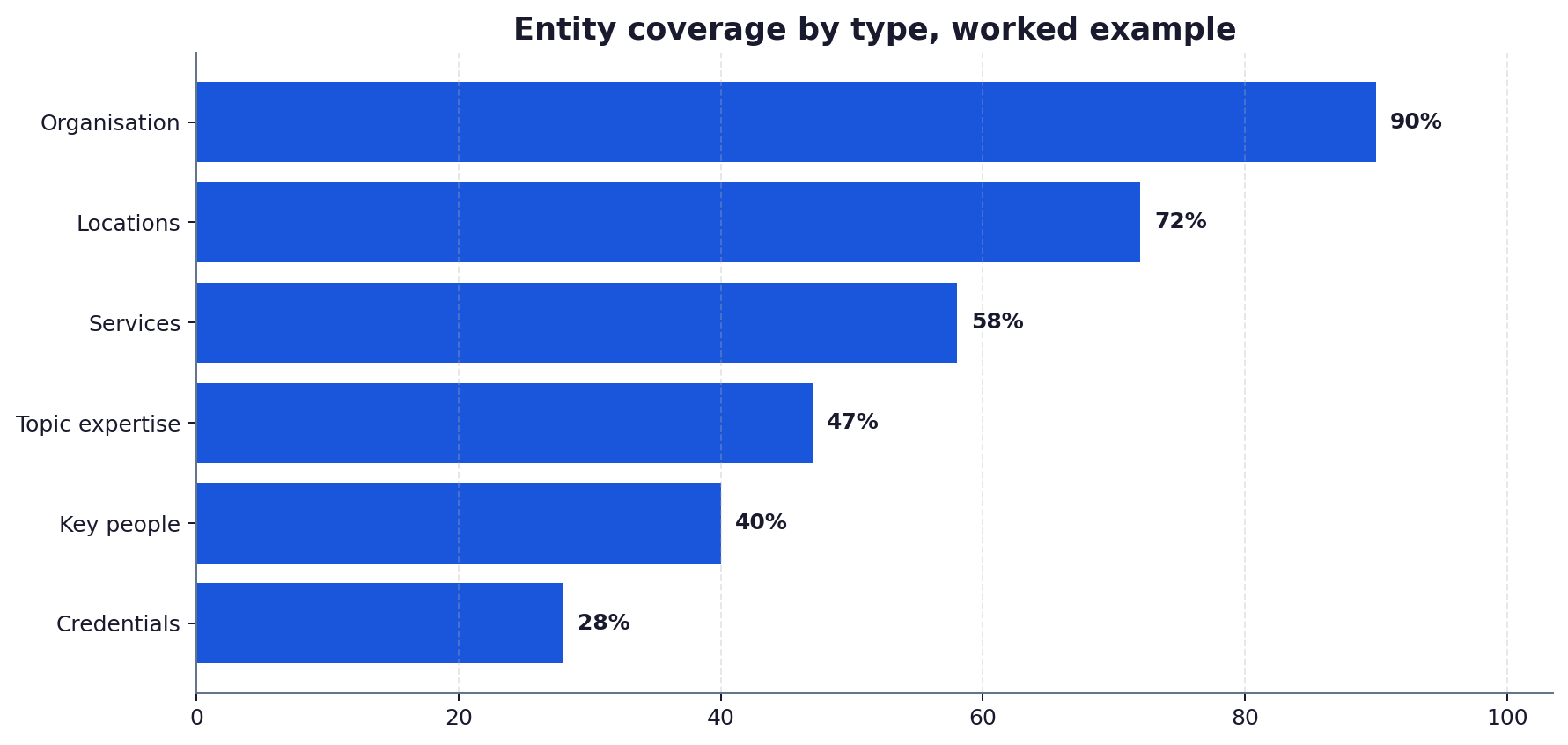
Crawl your site and list every entity your content names: the organisation, its people, its services or products, its locations, its credentials and the topics it claims expertise in. The goal is an inventory, not a judgement yet. A professional-services site typically surfaces six entity classes: organisation, key people, services, locations, credentials and topic expertise.
Step 3: map your entities to the reference graph
For each entity you found, check whether the reference graph knows it and how it is described. Your organisation may have a sparse Wikidata item or none at all. Your senior people may be entirely absent. Your services may exist only as words on a page with no structured definition. This mapping is where the gaps start to appear: an entity you treat as central may be invisible to the graph the engine consults.
Step 4: score coverage by entity type
Convert the mapping into a score per entity type: what share of the entities in that class are defined, linked and consistent. Coverage is rarely uniform. Organisations usually score well because a homepage and an about page define them. People, credentials and individual services score badly because they live in prose without schema, without sameAs links to authoritative profiles, and often with inconsistent naming across pages.
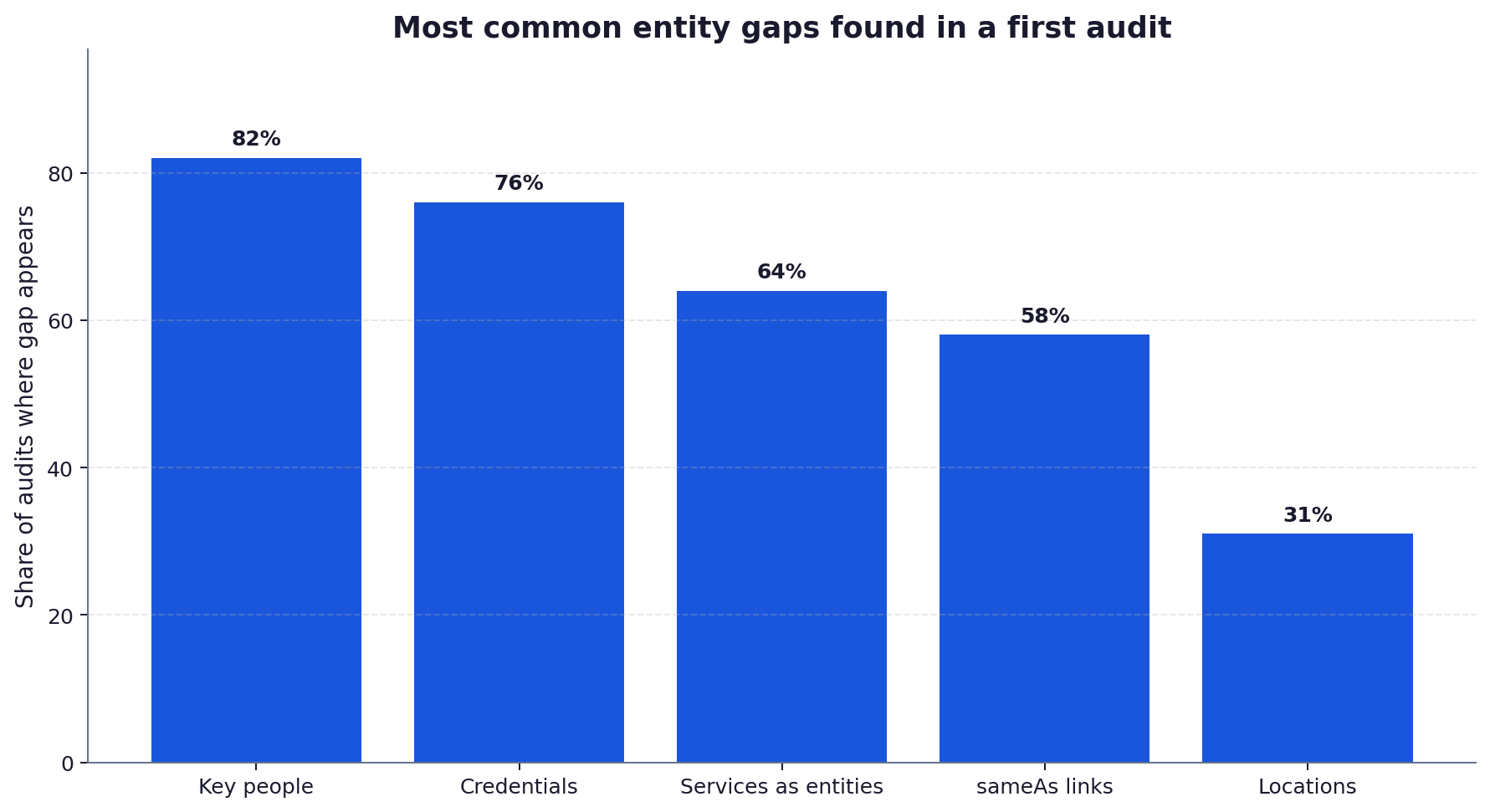
Step 5: find and document the gaps
A gap is any entity that is commercially important but missing, under-defined or inconsistently named. Three patterns dominate. Missing entities are people, credentials or services that never appear as structured data. Under-defined entities exist but lack relationships, such as a service with no provider link or a person with no employer link. Inconsistent entities are named three different ways across the site, so the engine cannot tell they are the same thing.
Step 6: prioritise gaps by commercial value
Not every gap is worth closing. Rank them by how directly the entity supports a query you want to win. A missing credential entity matters enormously for a YMYL query where trust is the gating factor, and barely at all for a top-of-funnel topic. Closing the gaps that sit on high-intent commercial queries first gives you citation gains where they convert.
Step 7: fix gaps with schema and supporting content
Each gap closes in one of two ways. Structural gaps close with schema: declare the entity with the right Schema.org type, link it to its relationships with properties such as employee, provider and areaServed, and add sameAs links to authoritative profiles like Wikidata, Companies House or a professional register. Substantive gaps close with content: if an entity has no real page defining it, the engine has nothing to cite, so build the page first and mark it up second.
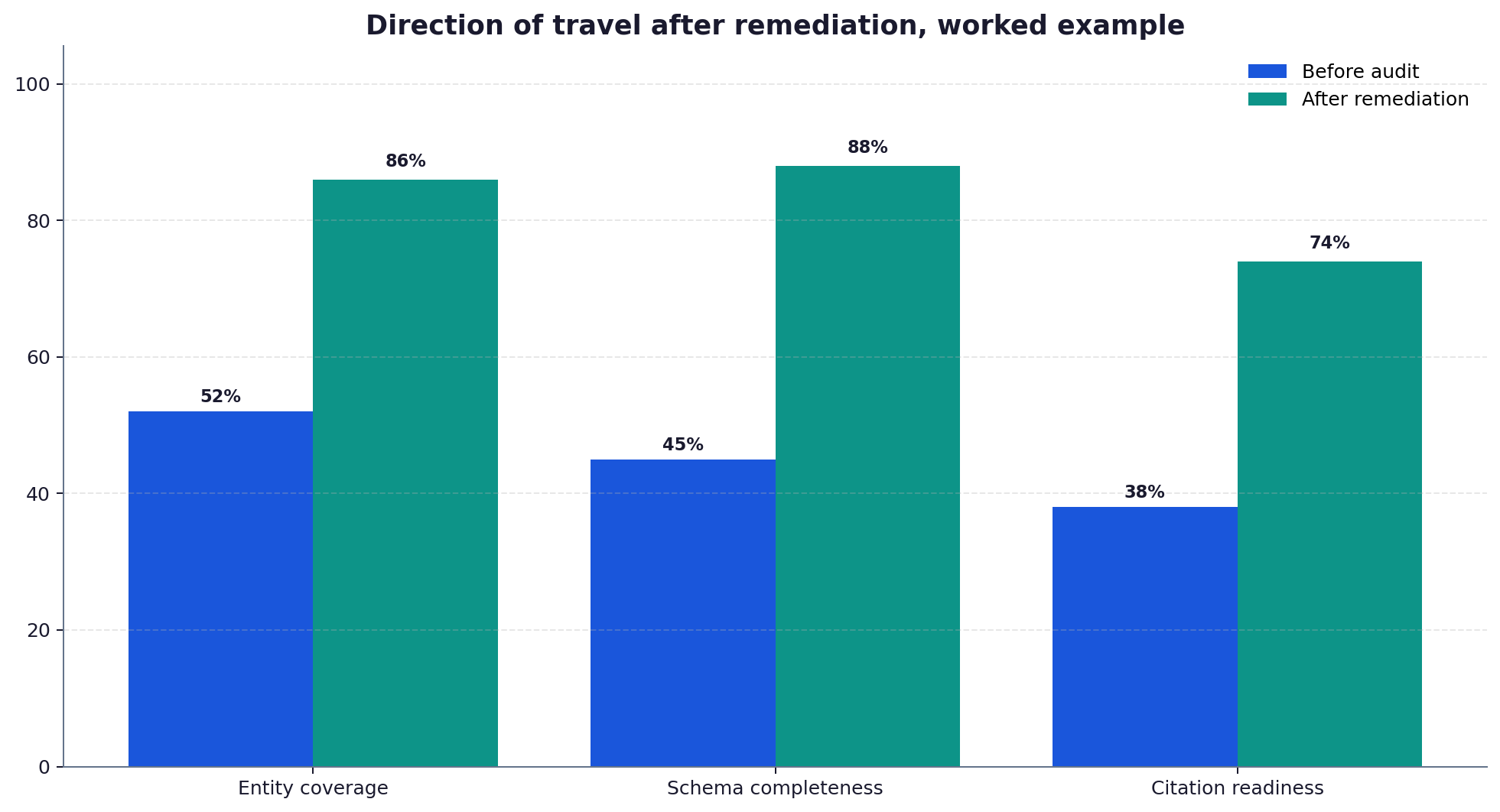
Turning the audit into a programme
An entity-gap audit is not a one-off. New services, new people and new locations all open fresh gaps, and reference graphs change as Wikidata and Google update their records. The useful output is a living register: every important entity, its coverage state, its priority and its fix. Worked through once a quarter, it keeps the facts an engine needs to cite you complete, current and consistent, which is the quiet foundation under every other generative SEO tactic.
Frequently asked questions
What is an entity-gap audit?
It is a structured comparison between the entities your content defines and the entities a reference knowledge graph expects to find. You inventory the people, organisations, services, locations, credentials and topics your site covers, map them to a graph such as Wikidata or the Google Knowledge Graph, score how completely each is defined and linked, and produce a ranked list of missing or weak entities to fix. The output tells you exactly which facts AI engines currently cannot verify about you.
Should I audit against Wikidata or the Google Knowledge Graph?
Use both. Wikidata is open and queryable, so it is the better model for understanding how an entity relates to others and for adding sameAs links. The Google Knowledge Graph, reached through its Search API, shows what Google already associates with your brand, which is closer to what an answer engine inherits. Most audits use Wikidata for the entity model and the Google graph to check your existing brand record.
Which entity gaps matter most?
Key people, credentials and individual services are the gaps that appear most often and matter most, because they carry the trust signals AI engines weigh heavily on commercial and YMYL queries. Organisations usually score well already because a homepage defines them. Prioritise gaps that sit on high-intent queries you want to win, because closing those produces citation gains where they convert rather than coverage for its own sake.
How do I fix an entity gap once I find it?
Structural gaps close with schema: declare the entity with the correct Schema.org type, link its relationships using properties such as employee, provider and areaServed, and add sameAs links to authoritative profiles. Substantive gaps, where no real page defines the entity, close with content first and markup second, because an engine cannot cite a page that does not exist. Consistency matters throughout: name each entity the same way everywhere.
How is this different from a normal schema audit?
A schema audit checks whether your markup is valid. An entity-gap audit checks whether the right entities exist at all and whether they are complete relative to an external reference. Valid schema on an incomplete entity set still leaves gaps an engine notices. The entity-gap audit starts from the graph the engine reasons over and works back to your content, which catches missing entities that a markup-validity check would never flag.
How often should I run an entity-gap audit?
Quarterly is a sensible cadence for most sites. New services, people and locations open fresh gaps, and reference graphs update their records over time, so a register that was complete in January drifts by April. Treating the audit as a living register, rather than a one-off project, keeps the entity facts an engine needs current and consistent, which protects the citation gains the first audit earned.
Sources and references
- Introducing the Knowledge Graph: things, not strings. Google, 2012
- Knowledge Graph Search API. Google, 2026
- Wikidata: a free and open knowledge base. Wikimedia / Wikidata, 2026
- Organization, Person and Service types. Schema.org, 2026
- GEO: Generative Engine Optimization. arXiv (Aggarwal et al.), 2024
- How structured data shapes AI Overviews. Ahrefs, 2026
An entity-gap audit tells you what to build; a free AI visibility report tells you whether the gaps are already costing you citations.
Change log
- 2026-06-11: Initial publication.