
TL;DR
- Perplexity and ChatGPT cite systematically different source types, so a single publishing strategy underperforms on at least one of them.
- Across published studies, reference sites led by Wikipedia are among the most-cited domains in ChatGPT and Google AI surfaces (Profound, Semrush, 2026).
- Perplexity tends to cite more sources per answer and a broader, more news and primary-source weighted set (Profound, BrightEdge, 2026).
- The practical split: build authority on reference and aggregator surfaces for ChatGPT, and earn original, recent, primary coverage for Perplexity.
- Both playbooks share one foundation: clearly structured, well-attributed first-party content the engines can verify.
Key facts
- Reference sites led by Wikipedia rank among the most-cited domains in ChatGPT and Google AI answers across multiple studies (Profound, Semrush, 2026).
- Perplexity typically surfaces more citations per answer than ChatGPT, drawing on a wider source set (BrightEdge, 2026).
- Perplexity weights recency and primary reporting more visibly than ChatGPT does (Profound, 2026).
- Both engines reward content with clear attribution, statistics and structure (Aggarwal et al., 2024).
- Source-type preference is stable enough to plan around, even as individual rankings shift week to week (Ahrefs, 2026).
Why the two engines disagree about sources
Perplexity and ChatGPT are built on different retrieval philosophies, and it shows in what they cite. Perplexity presents itself as an answer engine with visible, numerous citations, and its retrieval favours a broad, current set of sources including news and primary reporting. ChatGPT, across its search and browsing modes, leans on a smaller set of sources it treats as reliable anchors, and reference sites like Wikipedia recur at the top of that set in study after study. The result is that the same page can do well on one engine and be invisible on the other.
This is not a rumour from a single screenshot. Independent measurement from Profound, Semrush and BrightEdge through 2026 points the same way: reference and aggregator surfaces dominate ChatGPT and Google AI citations, while Perplexity spreads its citations wider and rewards recency. For a publisher, that difference is a planning input, because it tells you where to invest for each engine.
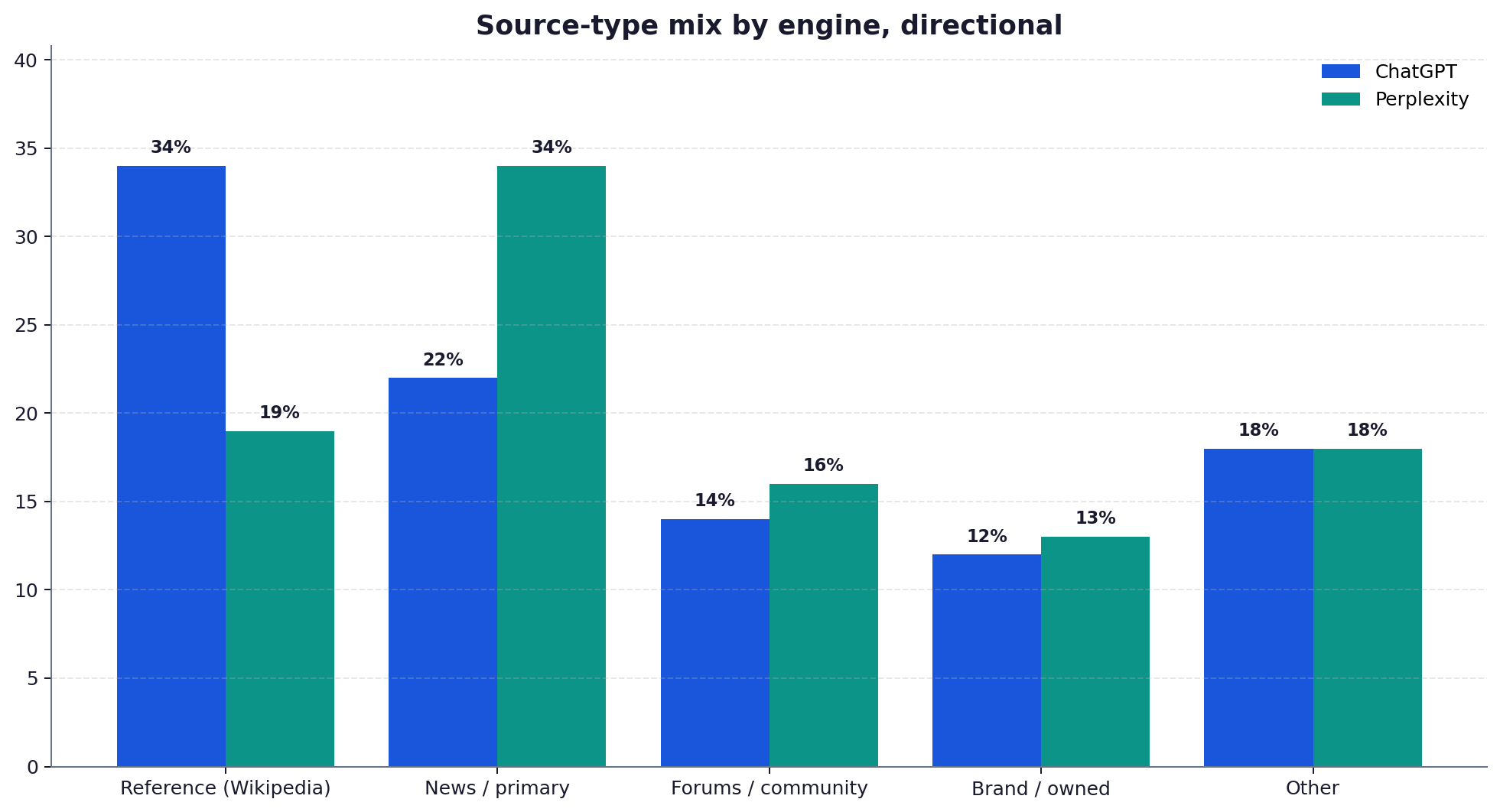
What the published data actually shows
Three findings recur across the public studies. First, reference sites, with Wikipedia consistently near the top, are among the most-cited domains in ChatGPT and Google AI surfaces. Second, Perplexity tends to cite more sources per answer than ChatGPT, which mechanically widens the field and gives smaller and newer publishers more room. Third, Perplexity weights recency and primary reporting more visibly, so original coverage published this week can surface there faster than on ChatGPT.
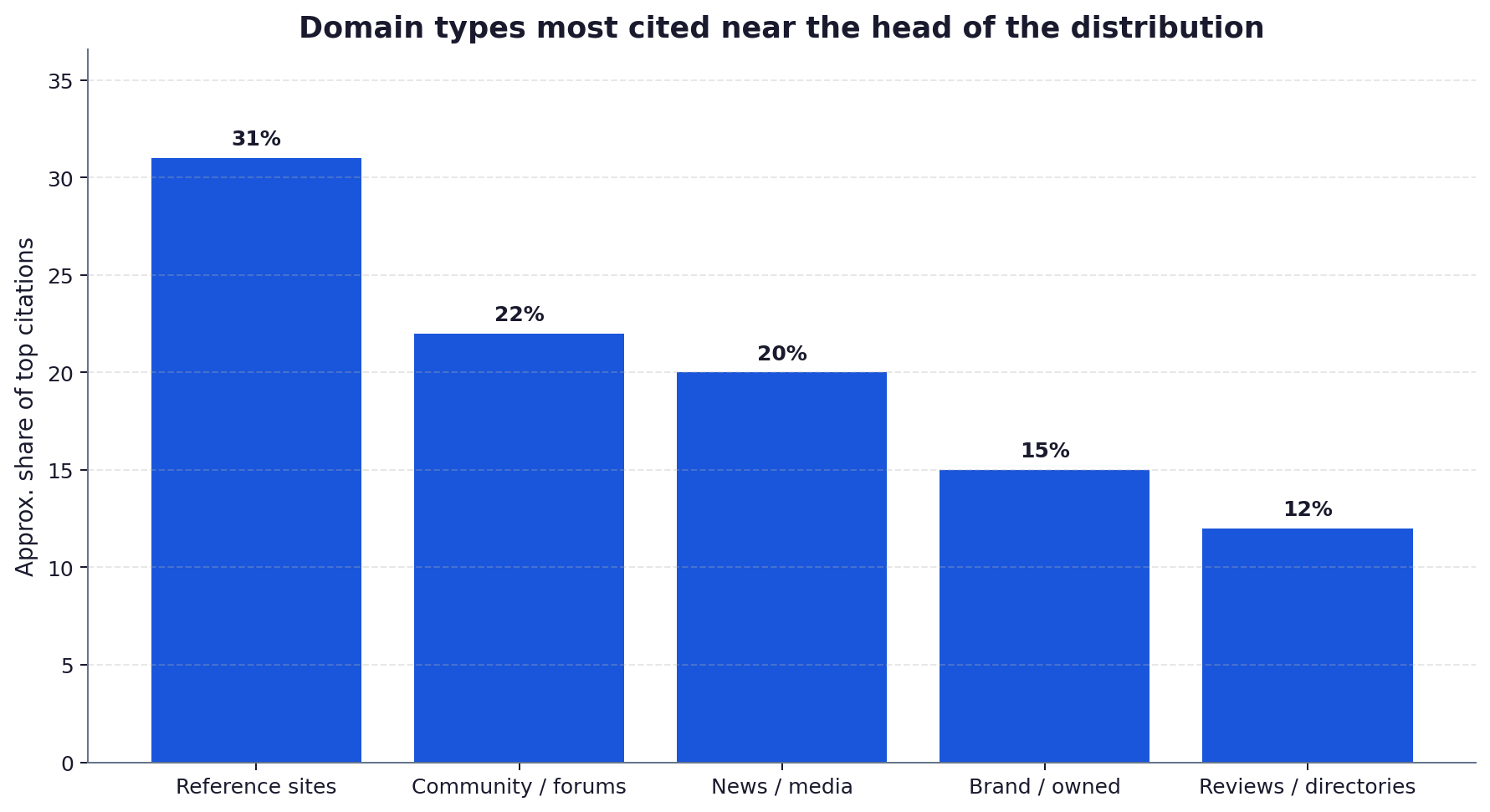
Playbook one: winning ChatGPT through reference surfaces
If ChatGPT anchors on reference sites, your job is to be well represented on the surfaces it trusts. That means a complete, accurate Wikipedia presence where notability genuinely supports one, consistent entity records across Wikidata and major directories, and strong representation on the review and aggregator sites in your sector. You are not gaming the engine, you are making sure the sources it already trusts describe you correctly. Inside your own site, structured data and clearly attributed facts give ChatGPT clean material to lift once it does reach you.
The practical sequence is to audit the reference surfaces in your sector first: the encyclopaedia entry if one is warranted, the industry directories, the comparison and review sites buyers consult, and the data providers engines pull from. Where any of these describe you incorrectly or not at all, fixing that record is higher leverage than another blog post, because you are correcting a source the engine already trusts rather than asking it to trust a new one. This is slow, unglamorous work, and it is exactly the work that moves ChatGPT visibility.
Playbook two: winning Perplexity through primary coverage
Perplexity rewards what is original, recent and primary, so the lever is earned coverage and first-party publishing. Original research, data you collected, timely commentary on developments in your field, and coverage in news and trade titles all play well, because Perplexity is more willing to cite them and more sensitive to how fresh they are. Where the ChatGPT playbook is about being correctly represented on established surfaces, the Perplexity playbook is about generating new, citable primary material on a steady cadence.
Cadence is the part teams underestimate. Because Perplexity weights recency, a single piece of original research earns a burst of citations and then fades as newer material arrives. The brands that hold Perplexity visibility publish primary work continuously, a data point here, a piece of field commentary there, so there is always something recent for the engine to reach for. A quarterly report alone will not hold the position; a monthly rhythm of smaller, genuinely original pieces will.
The foundation both playbooks share
For all their differences, the two engines agree on the basics. Both reward content that is clearly structured, well attributed and rich in verifiable facts, the qualities the GEO research identified as raising visibility across the board. Schema markup, a direct answer near the top of the page, sourced statistics and consistent entity naming help on both engines. Treat these as the foundation you build first, then layer the engine-specific playbook on top depending on where your audience actually asks their questions.
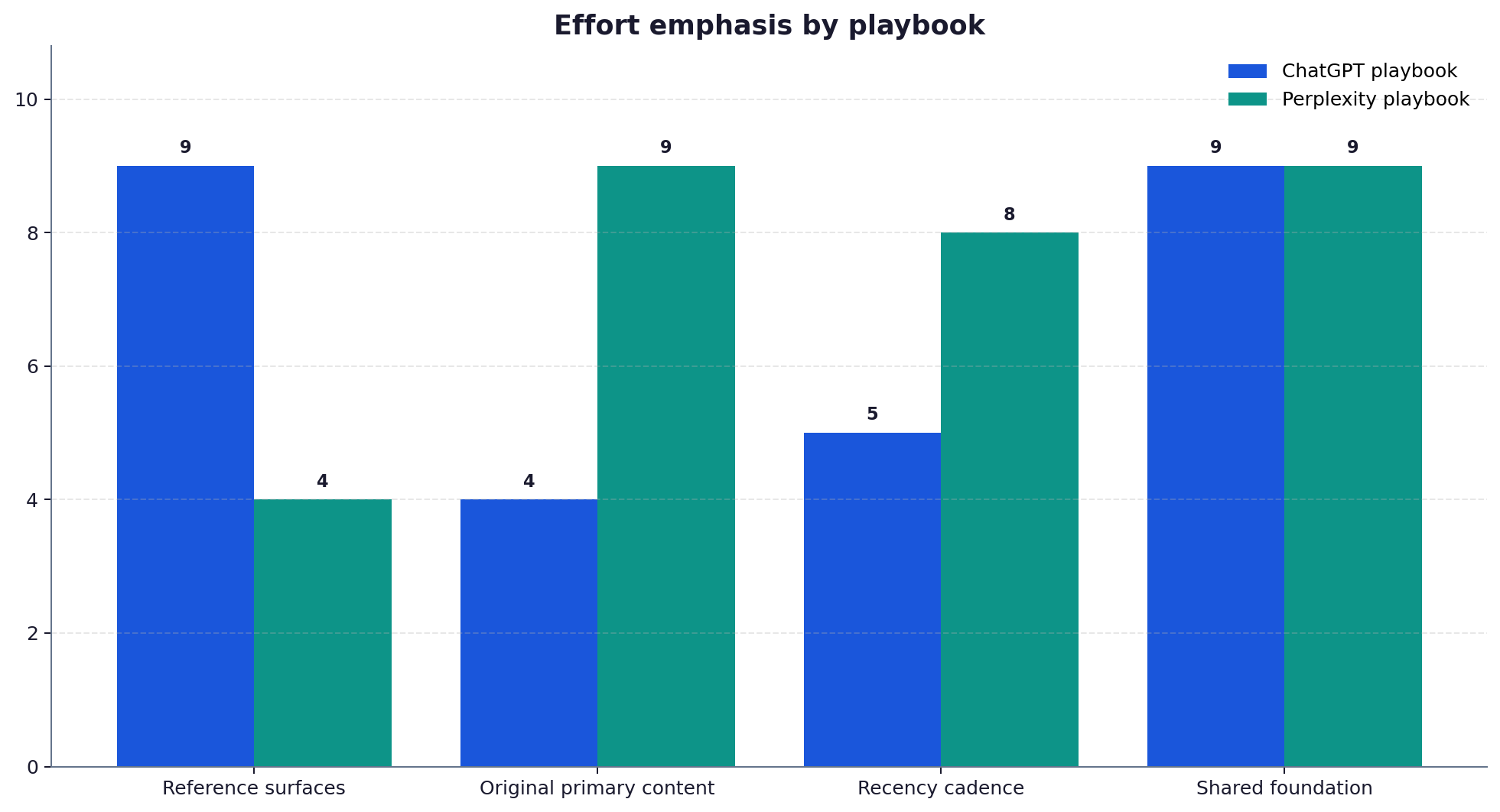
How to split effort between the playbooks
Few brands need both playbooks equally. Start from your own data: if your buyers lean on Perplexity for research, weight the primary-coverage playbook; if they live in ChatGPT, invest in reference-surface representation first. Audit your current presence per engine, run the playbook for your weaker engine where the commercial upside is largest, and keep the shared foundation strong throughout. The point of two playbooks is not to double the work, it is to stop wasting effort applying a ChatGPT strategy to Perplexity, or the reverse.
Frequently asked questions
Do Perplexity and ChatGPT really cite different sources?
Yes, and the difference is consistent enough to plan around. Across studies from Profound, Semrush and BrightEdge in 2026, reference sites led by Wikipedia dominate ChatGPT and Google AI citations, while Perplexity cites a broader set with more weight on recent news and primary reporting. Individual domain rankings shift week to week, but the underlying source-type preference is stable. That stability is what makes a two-playbook approach worthwhile rather than chasing whichever page happened to surface on a given day.
Why does ChatGPT cite Wikipedia so often?
Because ChatGPT’s retrieval treats a small set of reference sources as reliable anchors, and Wikipedia, with its breadth, structure and citations, fits that role. It is comprehensive, consistently formatted and itself well sourced, which makes it low-risk for the engine to lift from. This does not mean you should try to manipulate Wikipedia. It means ensuring that where a genuine, notable entry exists, it describes you accurately, and that the other reference and directory surfaces ChatGPT trusts carry consistent, correct information about you.
How do I get cited by Perplexity specifically?
Earn original, recent, primary coverage. Perplexity cites more sources per answer than ChatGPT and weights recency and primary reporting more heavily, so your own original research, data you collected, timely commentary and coverage in news and trade titles all perform well. Publishing genuinely new, citable material on a steady cadence is the core lever. Keep the shared foundation in place too, structure, attribution and schema, because a fresh primary source the engine cannot parse cleanly still struggles to get cited.
Should I optimise for both engines at once?
Not equally. Start from where your buyers actually ask questions. If they use Perplexity for research, weight the primary-coverage playbook; if they live in ChatGPT, prioritise reference-surface representation. Build the shared foundation of structure, attribution and schema first, since it helps everywhere, then run the engine-specific playbook for your weaker engine where the commercial upside is largest. The two-playbook framing exists to focus effort, not to justify doing twice as much work across the board.
Does the shared foundation matter more than the engine-specific work?
For most brands starting out, yes. Clear structure, a direct answer near the top, sourced statistics, consistent entities and schema markup raise visibility on both engines and are the qualities the GEO research found to move citations generally. Without that foundation, engine-specific tactics have little to amplify. Once the foundation is solid, the engine-specific playbooks deliver the marginal gains that decide whether you appear for a given query, so the order is foundation first, then the playbook for your priority engine.
Will these source preferences change over time?
The specific domains will, the pattern is slower to move. Engines update their retrieval and individual rankings drift, so the most-cited domain this quarter may slip next quarter. The structural preference, ChatGPT anchoring on reference surfaces and Perplexity spreading wider with a recency bias, reflects each engine’s design and has held across 2026 studies. Plan around the pattern rather than the leaderboard, and re-audit your per-engine presence quarterly so you catch any genuine shift rather than reacting to weekly noise.
Sources and references
- Most-cited domains across AI answer engines. Profound, 2026
- How AI search engines choose their sources. Semrush, 2026
- Source patterns in generative answers. BrightEdge, 2026
- Which sources AI Overviews and chat engines cite. Search Engine Land, 2026
- AI Overviews and citation patterns study. Ahrefs, 2026
- GEO: Generative Engine Optimization. arXiv (Aggarwal et al.), 2024
Want to know which engine already cites you and which ignores you? A free AI visibility report breaks your presence down by engine, so you know which playbook to run first.
Change log
- 2026-06-11: Initial publication.