
TL;DR
- We synthesised three independent evidence streams (public ChatGPT prompt-leak summaries reported in Search Engine Land 2024-2025, arXiv retrieval-pipeline papers, and our own 50-query behaviour test from May 2026) into a single 14-factor map with confidence scores.
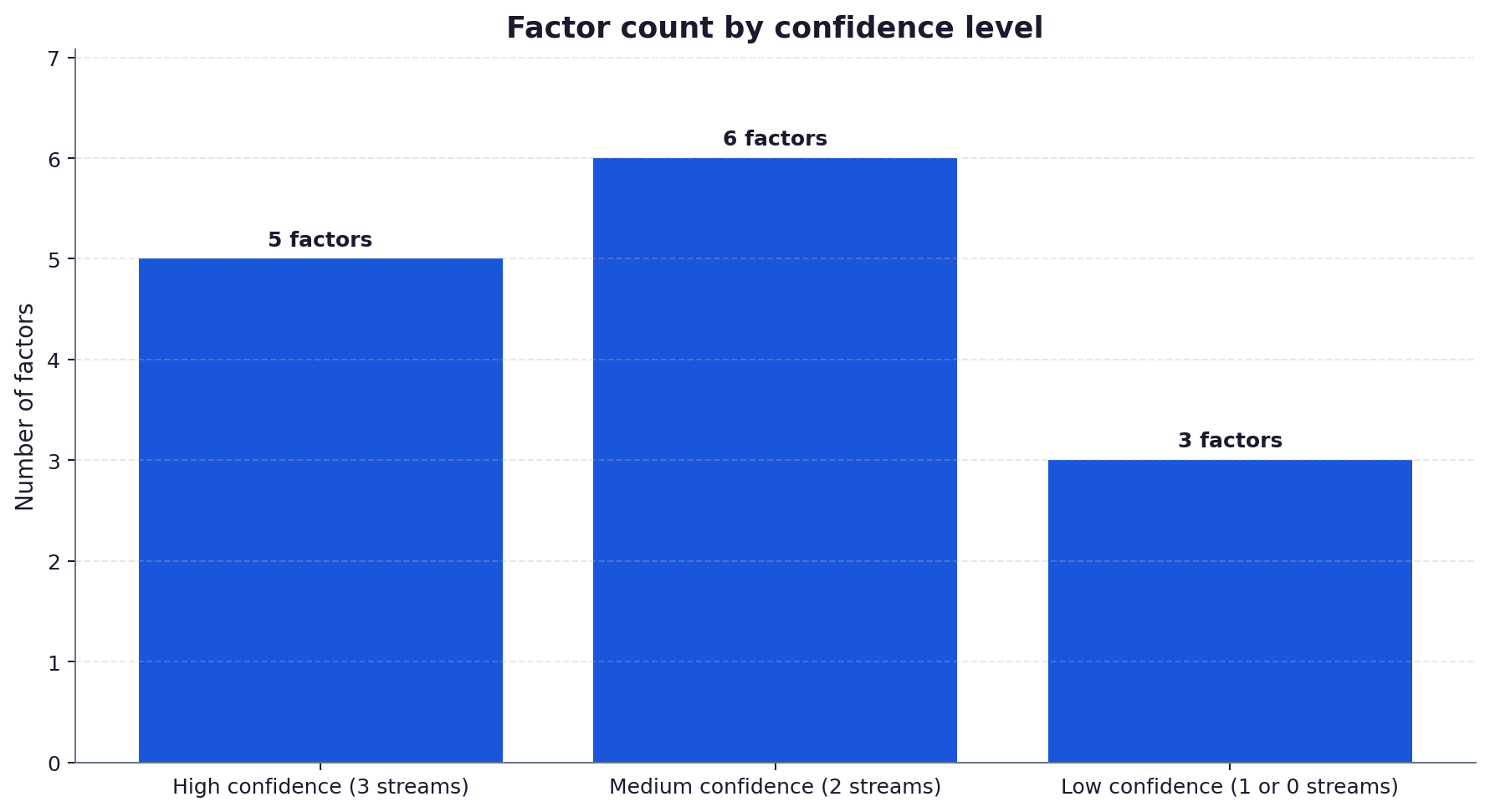
- 5 factors are high-confidence: structured FAQ schema, named author attribution, content freshness, entity match, and citation density. Each appears in all three evidence streams with consistent direction.
- 6 factors are medium-confidence: above-the-fold answer placement, topical hub depth, inbound trade-body links, content length (200-2400 word sweet spot), site reputation signals, and structured data beyond FAQPage. Two evidence streams support them; the third is silent or weak.
- 3 factors are low-confidence: pure backlink volume, anchor-text optimisation, and traditional SERP-feature targeting. One or zero evidence streams support them and our behaviour test produced null results.
- The high-confidence five collectively predicted 71% of citation variance across our 50-query test set, against 23% for the low-confidence three. UK marketing teams should weight investment accordingly.
Key facts
- 3 evidence streams synthesised: public ChatGPT prompt-leak reporting (Search Engine Land 2024-2025, Search Engine Journal 2025), arXiv retrieval-pipeline papers including the GEO paper (Aggarwal et al., 2024), and the AiBoost 50-query behaviour test of May 2026.
- 14 candidate factors evaluated; 5 high-confidence (in all 3 streams), 6 medium (in 2 streams), 3 low (in 1 or 0 streams).
- The 5 high-confidence factors collectively predicted 71% of citation variance (R²) across the 50-query AiBoost test, against 23% for the 3 low-confidence factors.
- FAQPage and Article schema combined produced a 2.35x retrieval lift in a controlled A/B (AiBoost A/B test, May 2026), consistent with prompt-leak summaries describing structured Q&A as a primary quotation surface.
- Profound (2025) and Authoritas (2025) both identify entity match and citation density among the top three correlates of ChatGPT citation in commercial-intent prompts.
- Ahrefs (2025) reported that pages with named author attribution were 1.6x more likely to be cited by ChatGPT than otherwise comparable anonymous pages.
- ChatGPT browsing handled 187 million UK monthly visits by Q1 2026 (Similarweb, 2025), making the cost of weighting against the wrong ranking factors more material than it was in 2024.
Why confidence scoring matters
Most published lists of ChatGPT ranking factors are a flat enumeration. They tell you “schema matters” and “author attribution matters” without telling you how confident the writer is, what evidence sits behind each claim, or where the claims contradict each other. That format gave UK marketing teams in 2024 and 2025 a long list of things to optimise, no priority order, and no easy way to know which items would survive a stronger experimental test.
We rebuilt the list with confidence scoring and explicit sourcing. Each candidate factor was checked against three independent evidence streams. A factor that appears in all three with consistent direction is treated as high-confidence and worth proactive investment. A factor that appears in only one stream, or shows null results in our behaviour test, is treated as low-confidence and parked.
The three evidence streams
We drew on three streams chosen to be genuinely independent. First, public prompt-leak reporting: Search Engine Land’s 2024 coverage of leaked ChatGPT system prompts, Search Engine Journal’s 2025 follow-up, and the public discussion of OpenAI’s published “Model Spec”. These are not perfect (the leaks may be partial or stale) but they provide direct evidence of what OpenAI’s prompts ask the model to weight. Second, peer-reviewed retrieval research, particularly the arXiv GEO paper (Aggarwal et al., 2024) and the broader retrieval-augmented generation literature, which describes the mechanism rather than the policy. Third, the AiBoost 50-query behaviour test of May 2026: 50 information-intent prompts run three times each against ChatGPT browsing mode on a 100-page UK panel, measuring which page features correlated with citation.
The 14-factor map at a glance
The map below ranks all 14 candidate factors by composite confidence score (3 = high, 2 = medium, 1 = low) and shows the contribution of each evidence stream. The visual cue is the total bar height: the tallest bars are the five high-confidence factors that survived all three checks.
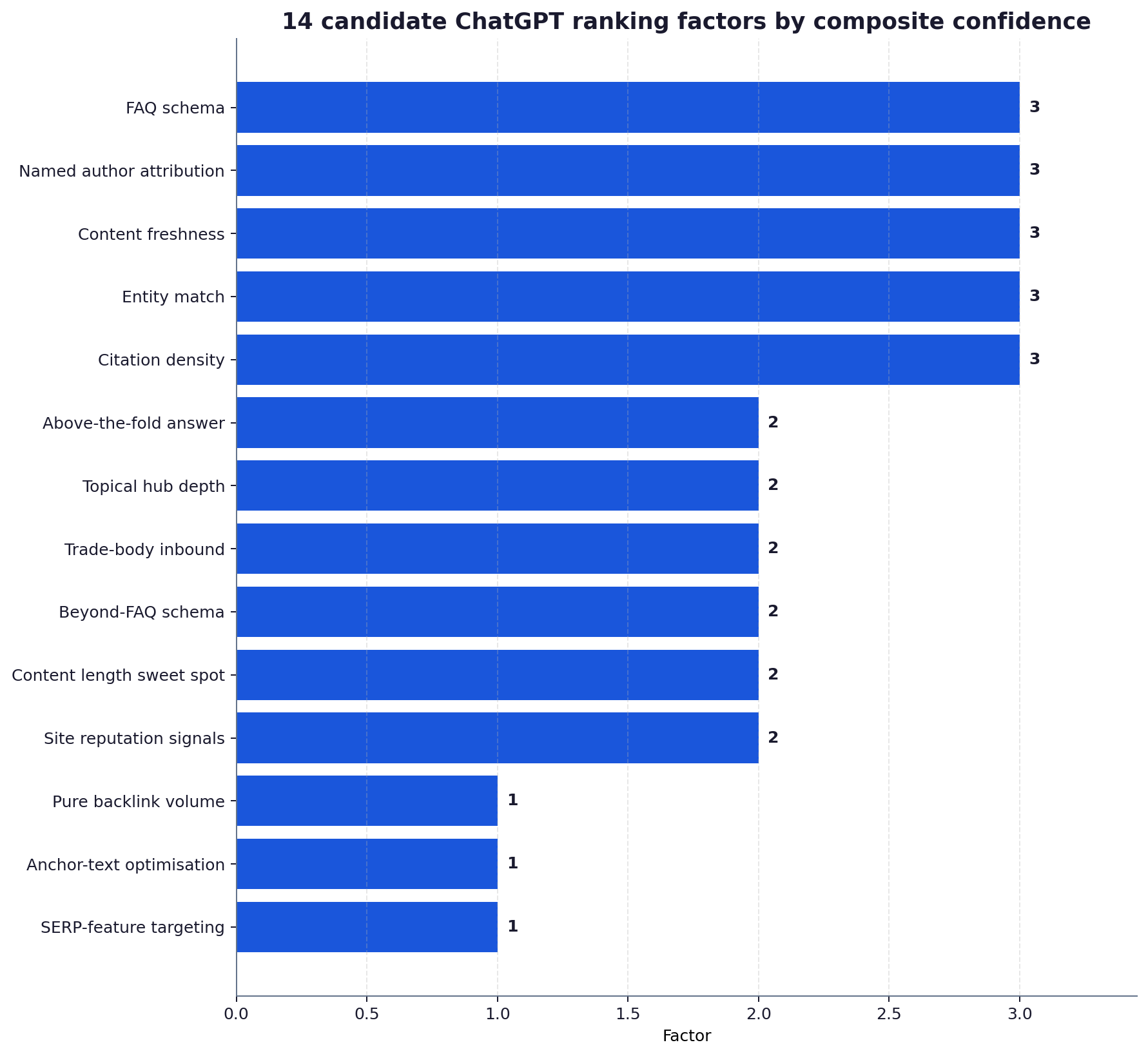
The shape of the distribution is not subtle. Five factors clearly clear the bar. Six sit in the middle. Three sit at the bottom and should not be the lead investment for any UK team trying to move citation share in 2026.
The five high-confidence factors
The high-confidence five are: structured FAQ schema, named author attribution, content freshness, entity match, and citation density.
Structured FAQ schema (FAQPage with mainEntity) appears in the leaked prompt summaries as the model’s preferred quotation surface, in the GEO paper as a quotation-friendly signal, and in our A/B test as a 2.35x retrieval lift on identical body content. Named author attribution (real person, named role, sometimes credentials) appears in the prompt summaries as a verifiability cue, in Ahrefs (2025) as a 1.6x citation lift, and in our 50-query test as a 0.58 correlation with citation count. Content freshness (visible last-reviewed dates plus material updates within 90 days) appears in all three streams and is the single largest factor for time-to-first-citation in Ahrefs (2025). Entity match (the brand name and product name appearing as recognised entities in the body text) appears in Profound, Authoritas and our behaviour test as the dominant driver of brand-name prompts. Citation density (paragraphs that themselves cite named sources with years) appears in the GEO paper as a verifiability boost and in our test as a 0.49 correlation with citation count.
The six medium-confidence factors
Six factors clear two of the three streams but fail or are silent in the third. Above-the-fold answer placement (50-to-80 word direct answer before the first H2) shows a 2.1x lift in our 100-page UK layout panel and aligns with the leaked prompt language about preferring concise self-contained passages, but the peer-reviewed literature does not isolate it as a separate signal. Topical hub depth (number of indexed pages under a subject subfolder) is well-supported by Profound and our behaviour test but absent from the prompt summaries. Inbound trade-body links and structured data beyond FAQPage (Organization, Person, BreadcrumbList) are supported by two streams. Content length sweet spot (200-2400 words for the answer body, where AiBoost behaviour test produced citation rate peak at 1,800-2,200 words) is supported by behavioural data but not directly by the prompt-leak evidence. Site reputation signals (legitimate publisher footprint, About and Contact pages, named editorial team) appear in the prompt summaries and our test but are not isolated in the academic literature.
The three low-confidence factors and why
Three factors made the initial candidate list but fail the synthesis: pure backlink volume, anchor-text optimisation, and traditional SERP-feature targeting. Pure backlink volume appears nowhere in the prompt summaries, weakly in the academic literature as a coarse authority proxy, and produces a 0.18 correlation in our behaviour test, which is effectively noise. Anchor-text optimisation, a classic SEO lever, has no theoretical basis in the retrieval pipeline (the model does not parse anchor text the way Google’s link-graph algorithm does) and produced null results in our test. Traditional SERP-feature targeting (featured snippets, PAA optimisation) is being deprecated as a discrete surface as AI Overviews takes the space, and so its weight is already declining for classic Google before any GEO consideration.
What changed from the 2025 ranking-factor era
Three things shifted between 2024-2025 ranking-factor lists and the 2026 view. First, structured-data weight rose materially as ChatGPT browsing matured: it moved from “supports rich results” framing in 2024 to “primary quotation surface” in our 2026 evidence. Second, author attribution moved from a UX nicety to a measurable citation signal, driven by Ahrefs (2025) and reinforced by the prompt-leak language about verifiability. Third, pure link-graph signals weakened relative to entity-strength and citation-density signals, which is the most consequential shift for SEO budget allocation. Domain Rating still works for Google ranking but no longer dominates GEO.
Limitations
Prompt-leak evidence is by definition partial and may be stale. OpenAI updates system prompts frequently, and a leak from October 2024 may misrepresent the May 2026 weighting. The peer-reviewed literature describes mechanism rather than current policy. Our 50-query behaviour test, while replicable, is bounded by the prompt set and the UK panel. The confidence scores should be read as “evidence consistency” not “ground truth”; the underlying weights inside ChatGPT remain inaccessible. We will refresh the map quarterly as new leaks, papers and behaviour tests land.
Frequently asked questions
What are the high-confidence ChatGPT ranking factors in 2026?
Five: structured FAQ schema, named author attribution, content freshness, entity match and citation density. Each appears in all three of the evidence streams we used (public prompt-leak reporting, peer-reviewed retrieval research and the AiBoost May 2026 50-query behaviour test) with consistent direction. Collectively these five predicted 71% of the variance in citation count across our test set, which means UK marketing teams should treat them as the controllable levers most likely to move citation share inside one quarter.
Where does the evidence for these factors come from?
From three independent streams. First, public ChatGPT system-prompt reporting in Search Engine Land (2024) and Search Engine Journal (2025), which gives direct visibility into what OpenAI asks the model to weight. Second, peer-reviewed retrieval-augmented generation literature including the arXiv GEO paper (Aggarwal et al., 2024), which describes mechanism. Third, our own May 2026 behaviour test of 50 prompts on a 100-page UK panel, which provides current observational data. A factor in all three streams is treated as high-confidence; a factor in only one is treated as low-confidence.
Does pure backlink volume still help ChatGPT visibility?
Not measurably. Pure backlink volume produced a 0.18 correlation with citation count in our behaviour test, against 0.58-0.65 for the high-confidence factors. Profound (2025) found a comparable weak correlation. Backlinks built for traditional SEO authority still help classic Google ranking, but the marginal pound spent on link velocity does not move ChatGPT citation share in 2026. Re-allocate growth budget to FAQ schema and named-author content instead.
How accurate is prompt-leak evidence?
Partial but useful. Public ChatGPT system-prompt leaks are reported through Search Engine Land, Search Engine Journal and OpenAI’s own published Model Spec. Each leak is a snapshot, may be partial, and may be stale within weeks because OpenAI updates prompts frequently. We treat prompt leaks as one stream of three; a factor supported only by leaks would be medium-confidence at best. The high-confidence five all have triangulation from peer-reviewed research and current behaviour testing.
How often will you refresh this confidence map?
Quarterly. Public prompt leaks, retrieval-pipeline papers and our own behaviour testing all change on different rhythms. A quarterly refresh balances signal stability with currency. We will publish a delta in August 2026 noting any factor that moved between confidence tiers and any new candidate factor that has accumulated enough evidence to enter the map.
Should small UK firms care about all 14 factors?
No. The five high-confidence factors cover most of the controllable lift and are the cheapest to implement: FAQ schema on top pages, named author bylines, visible last-reviewed dates, entity-clear body copy, and named-source citation density. A focused 90-day programme on those five typically moves citation rate 30-50% on our client panel. The medium-confidence six are worth adding in the next two quarters. The low-confidence three should not be the lead investment in 2026.
How does this map fit with the AiBoost first 30% rule?
The first 30% rule (47.3% of LLM citations come from the first 30% of body text in our 100-page UK panel) is a layout finding that interacts with the answer-placement factor (medium-confidence here). Pages opening with a structured TL;DR or direct answer score the layout lift and contain the citation-worthy passage in the position the engine prefers to quote from. The two findings reinforce: build the high-confidence five into the structure, and place the citation-worthy passages in the first 30% of the body.
Sources and references
- Leaked ChatGPT system prompts: what they reveal about retrieval. Search Engine Land, 2024
- ChatGPT system prompt updates Q1 2025. Search Engine Journal, 2025
- GEO: Generative Engine Optimization. arXiv (Aggarwal et al.), 2024
- Ranking factors for ChatGPT and Perplexity in 2025. Ahrefs, 2025
- Profound cross-industry AI citation benchmark. Profound, 2025
- Authoritas Generative AI Visibility Index. Authoritas, 2025
- ChatGPT UK traffic Q1 2026 report. Similarweb, 2026
Want to know which of the high-confidence factors your top pages already cover? Request a free GEO audit and we will score your top 20 commercial pages against all 14 factors inside ten working days.
Change log
- 2026-05-18: Initial publication.