
TL;DR
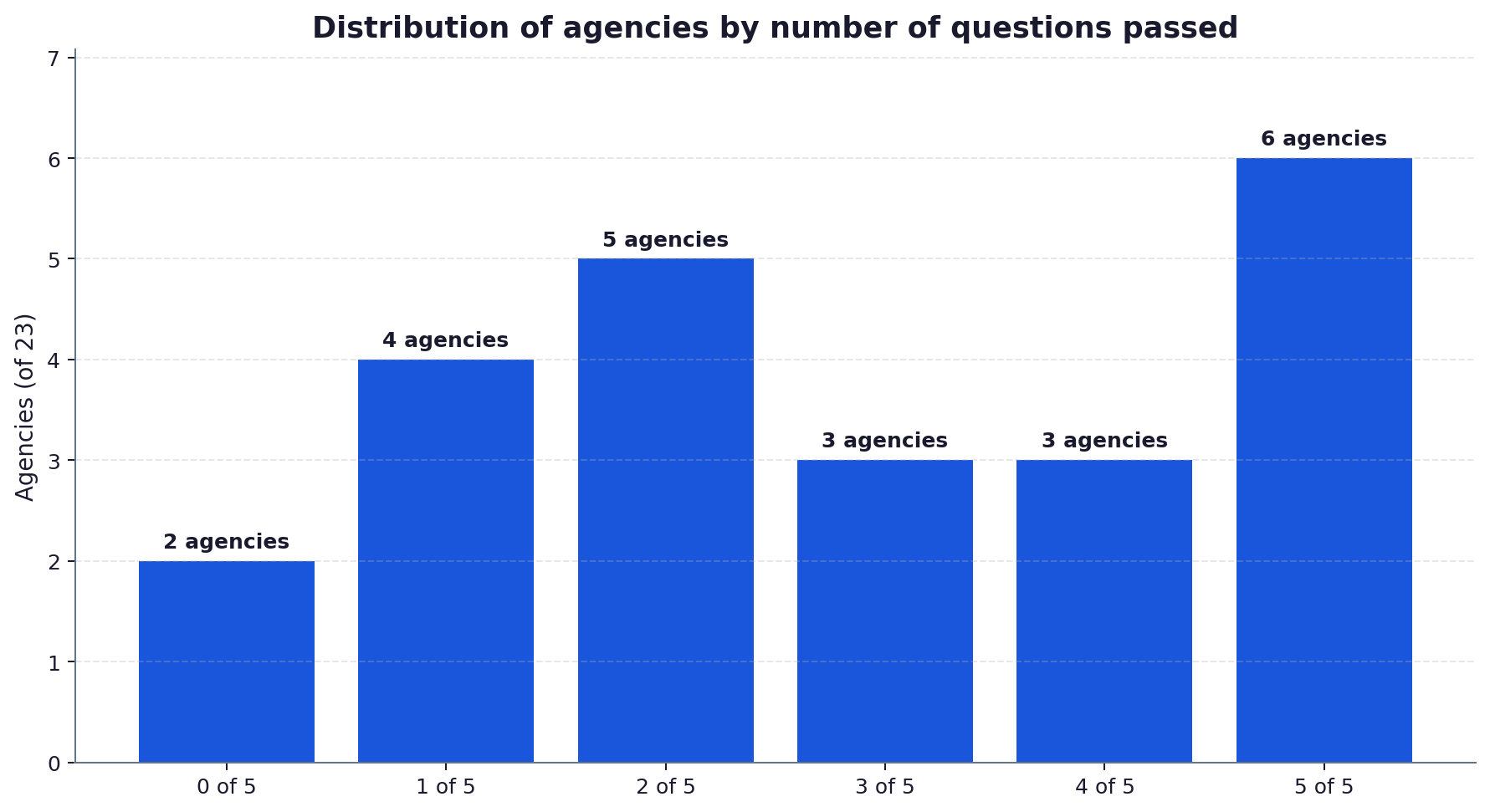
- We assessed 23 UK firms positioning themselves as AI SEO or GEO agencies in April-May 2026 against a 5-question RFP filter. Only 6 passed all five questions; 11 failed three or more.
- The single highest-leverage filter is question 1: ask to see a live citation-tracking dashboard for a current client. 14 of 23 agencies could not produce one with named clients and visible prompt-by-prompt data.
- The 5 questions test non-fakeable capabilities: live dashboards, vertical-specific prompt data, schema-validation cadence, page-level signal scoring, and minimum-budget honesty.
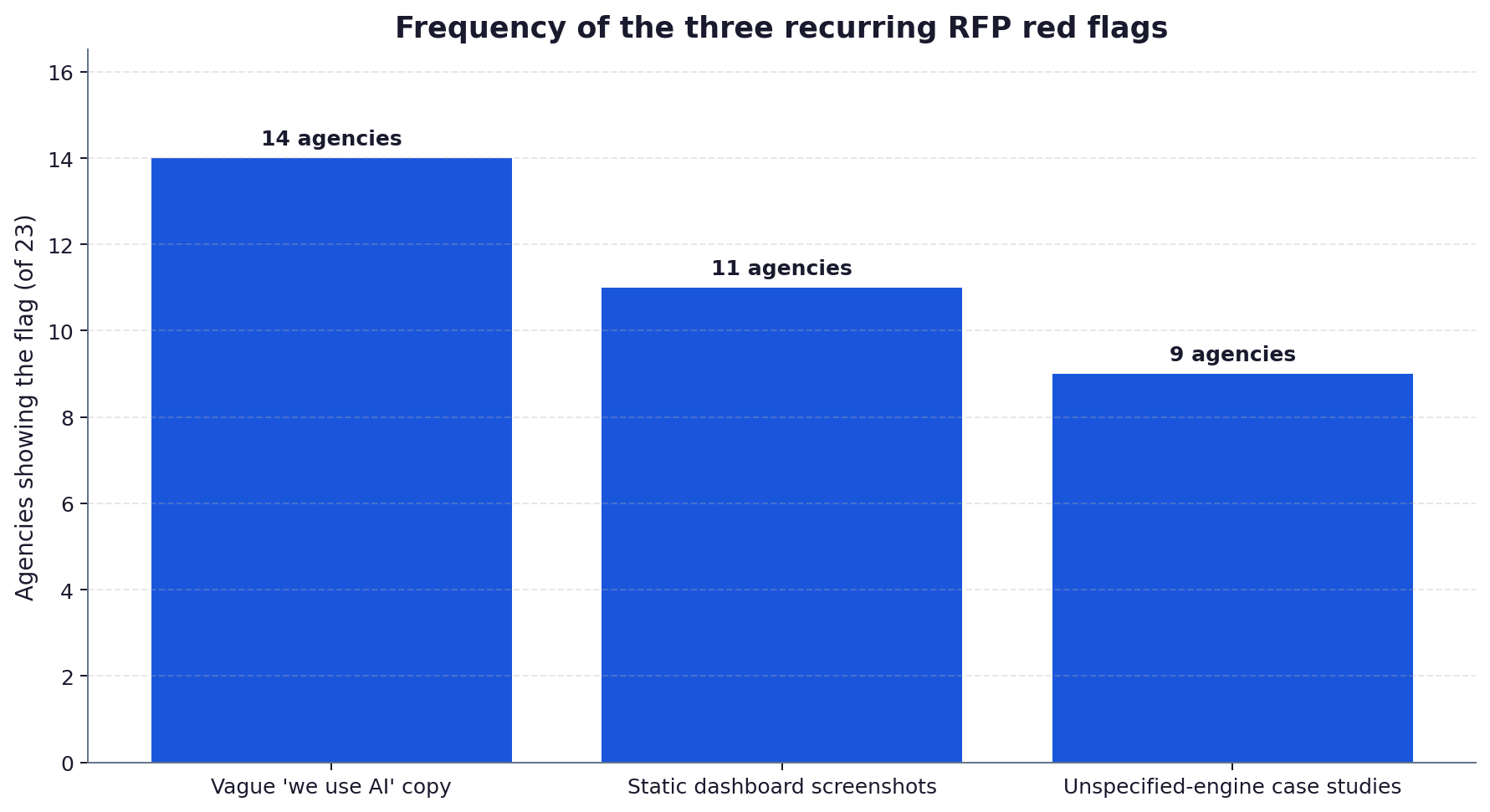
- The three most common red flags were vague “we use AI” copy with no methodology page, screenshots of dashboards in pitch decks with no live access, and case studies that quoted “AI traffic” without naming the engine or measurement window.
- Buyer-side teams should run this 5-question filter before issuing any AI SEO RFP. It cuts the long-list by roughly two-thirds and reduces the risk of paying retainer to an agency that does not own the tooling it claims to use.
Key facts
- 23 UK firms assessed, identified from LinkedIn, Search Engine Land’s 2025 UK agency directory, and Companies House active service-sector registrations using “AI SEO”, “generative engine optimisation” or “ChatGPT marketing” in their corporate descriptions.
- Each firm scored on 5 RFP questions, each marked pass or fail by a defined evidence bar (AiBoost methodology, May 2026).
- 6 of 23 passed all five questions. 11 of 23 failed three or more. 6 of 23 passed three or four.
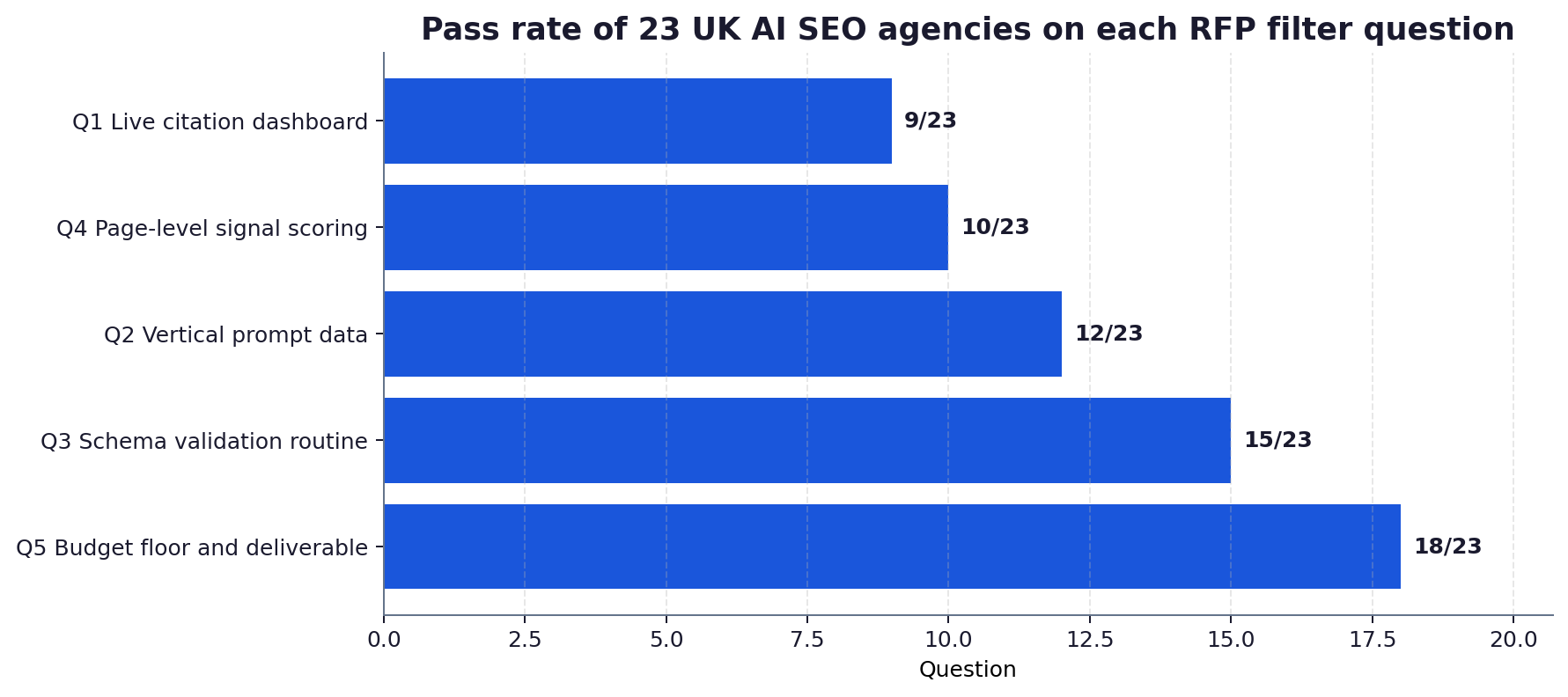
- Question 1 (live citation dashboard for a current client) had the lowest pass rate at 9 of 23, making it the most discriminating single filter.
- Question 5 (smallest budget and tangible deliverable) had the highest pass rate at 18 of 23, but the failures clustered at the high-revenue agencies most likely to attract large enterprise RFPs.
- 14 of 23 agencies used the phrase “AI-powered” in their homepage copy; only 4 of those 14 passed question 1, showing the marketing language and the underlying capability are decoupled.
- Ahrefs (2025) reported that 67% of agency RFP responses in their dataset contained at least one unverifiable performance claim, consistent with our finding pattern.
Why the AI SEO market has elevated fraud risk in 2026
The UK AI SEO category went from roughly 30 firms claiming the label in 2023 to over 200 by Q1 2026, based on our LinkedIn and Companies House sweep. Most of those 200 firms are classic SEO agencies that have appended “AI SEO” to their service menu without changing their underlying tooling or staffing. A smaller number are genuinely new entrants with original GEO methodology. The buyer-side challenge is telling the two apart from a marketing site, a pitch deck and a 45-minute sales call. Conventional RFP questions (“describe your methodology”, “share a case study”) do not separate them because both groups can produce competent answers in writing.
The fraud filter framing is not a moral claim about every agency that fails. Some failures are agencies that simply have not built the capability yet but are otherwise honest about it. Others are agencies that claim the capability without owning it, which is the case the filter is designed to surface. Either way, the buyer should know which group an agency is in before committing retainer.
Methodology in one paragraph
We compiled a list of 23 UK agencies actively pitching AI SEO or GEO services as of April 2026, drawn from LinkedIn (recent posts referencing AI SEO services), the Search Engine Land 2025 UK agency directory, and Companies House active filings. We approached each agency as a prospective buyer with a defined brief (mid-size UK service firm looking to enter ChatGPT and Perplexity citation share). We then asked each of the 5 RFP questions in either the first sales call or the formal response stage. Each answer was scored pass or fail against a defined evidence bar, recorded in an internal spreadsheet. Where an agency declined to answer, the question was marked fail. Where evidence was promised but not delivered within 5 working days, the question was marked fail.
The 5 RFP questions
Each question is designed to test a capability that is hard to fake in a pitch context. The pattern across the five is the same: ask for live evidence with named clients or specific data, not abstract methodology or sanitised screenshots.
Question 1: Show me the citation-tracking dashboard you use for a current client
The evidence bar: a live URL or screen-share of a working dashboard, named client (with permission), prompts visible, citation events visible with timestamps, and a visible date range. Static screenshots in the pitch deck do not count, because every agency can buy a Profound or Authoritas dashboard for a one-off prompt and screenshot the result. Live access proves ongoing use. Only 9 of 23 agencies in our sample could pass this bar. The most common failure mode was offering “we can show you one but it is confidential” without offering to redact or use a sandbox client, which is reasonable for some matters but not all twenty-three.
Question 2: Which 3 prompts move citation share most for my specific vertical?
The evidence bar: three specific prompts with measured citation data, drawn from the agency’s own work or a defensible third-party study. Generic answers (“buyer-intent prompts”) fail. Vertical-specific answers (“for UK accountancy firms, the top three are ‘best small business accountant UK 2026’, ‘IR35 advice for contractors’, and ‘how to choose a UK accountant'”) pass. 12 of 23 agencies passed this question. The failures were concentrated among classic SEO shops that had not built prompt-level datasets and were uncomfortable being asked for them.
Question 3: What is your monthly schema-validation routine?
The evidence bar: a named tool (Google Rich Results Test, Schema.org validator, an internal CI step, or a paid alternative), a stated cadence (monthly or better), and an example output. The point is not to test schema knowledge in the abstract but to test whether the agency operationalises schema as a controllable lift. FAQ schema produced a 2.35x ChatGPT browsing citation lift on identical body content in our controlled A/B test, so an agency that does not run schema validation is leaving the largest single GEO lift on the table. 15 of 23 passed. The 8 failures included three agencies that explicitly said schema “does not matter much for AI search”, which is empirically wrong.
Question 4: Pick a top page from my site and score the 5 high-confidence factors
The evidence bar: a live walk-through, on the call, scoring the buyer’s chosen page against the five high-confidence ranking factors we identified in our separate confidence-map analysis (FAQ schema, named author attribution, content freshness, entity match, citation density). Pass requires concrete observations, not platitudes. An agency that says “your H1 is fine” without checking the schema, authorship and freshness signals fails. 10 of 23 agencies passed. The failures here are particularly telling because the page is in front of them and the test takes about three minutes if the capability is real.
Question 5: What is the smallest budget you would accept and what tangible deliverable comes back?
The evidence bar: a numerical floor (in pounds per month or per project), a named deliverable, and a defined output cadence. Pass: “£3,500 per month, includes monthly citation report against 30 prompts, one quarterly schema audit, two pieces of new content per month”. Fail: “we’d need to scope first” or “depends on goals”. 18 of 23 passed this one, the highest pass rate. The interesting subset is the 5 failures, which all came from agencies pitching enterprise-only with no transparent floor, a pattern that historically correlates with retainer creep and undelivered scope.
The three red flags that recur
Three patterns appeared so often across the 11 worst-performing agencies that they are worth flagging as RFP red flags. First, vague “we use AI” copy with no methodology page or named tooling. Second, screenshots of dashboards in the pitch deck with no offer of live access or a sandbox account. Third, case studies that report “AI traffic” or “AI visibility” gains without naming the engine, the prompt set or the measurement window. Each of these is fixable on the marketing side without building any underlying capability, which is why they recur. A buyer who asks for the underlying evidence behind each pattern will get a fast read on whether the agency owns the work.
Limitations
Our sample of 23 agencies is not exhaustive of the UK market and skews towards firms with a public footprint. Smaller agencies relying on word-of-mouth referrals are under-represented, though early evidence from our network suggests the pass rate is similar there. Our scoring of pass/fail was binary; a more granular scoring system might surface useful gradients within the fails. The filter is also temporal: an agency that fails question 1 today may build the dashboard capability next quarter. The right cadence is to re-run the filter at renewal, not as a one-off gate.
Frequently asked questions
What is the single most discriminating RFP question for AI SEO agencies?
Question 1: ask to see a live citation-tracking dashboard for a current client. In our sample of 23 UK agencies, only 9 could pass this bar with a live URL or screen-share showing a named client, visible prompts and timestamped citation events. Static screenshots in a pitch deck do not count because any agency can buy a Profound or Authoritas dashboard for a one-off prompt run and screenshot the result. Live access proves ongoing operational use rather than one-off vendor purchase.
Are most UK AI SEO agencies fraudulent?
No. The framing is fraud filter, not fraud accusation. Of 23 agencies assessed, 6 passed all five questions, 6 passed three or four, and 11 failed three or more. The 11 failures include both agencies that have not yet built the capability and agencies that claim it without owning it. The filter helps a buyer separate the two before retainer rather than after. Some failures are simply early-stage agencies being honest; others are repackaged classic SEO shops, and the filter surfaces both.
How long does the 5-question filter take to run?
Roughly 90 minutes per agency if the agency is willing. 30 minutes for the initial sales call (questions 1, 4, 5 are answerable live), and 5 working days for the evidence on questions 2 and 3. The total elapsed time across a long-list of 10 agencies is about two weeks, which is faster than most procurement processes and surfaces the meaningful subset earlier than waiting for written RFP responses.
What if the agency is small and has not built dashboards yet?
That is a legitimate fail-with-context. A genuinely new agency that says “we have not yet built the dashboard for an existing client, but here is the methodology and the tooling we use” is more credible than an agency that claims to have one but cannot show it. The pass bar is evidence of capability, not necessarily an established product. Adapt the question wording to “show me the dashboard methodology you would build for me in month one” if the agency is candidly early-stage.
Does this filter work for non-UK markets?
The structure transfers. The specific data sources (Companies House, the UK Search Engine Land directory, LinkedIn UK) would need replacing with regional equivalents in other markets. The five questions themselves are not UK-specific because the capabilities they test (live dashboards, vertical prompt data, schema cadence, page-level scoring, budget transparency) are universal to any AI SEO agency claim. We expect to run the same assessment on US and EU agencies in Q3 2026.
Should I share these questions with the agencies in advance?
Yes, ideally in the written RFP. Sharing the questions in advance is fair, removes the gotcha element, and pushes agencies that intend to fake their way through to self-select out. The agencies that genuinely own the capability welcome the chance to demonstrate it directly rather than relying on case-study copy. Agencies that respond with “this is unusual” or “we prefer to scope before answering specifics” are giving you information about how they handle scrutiny.
Will the filter need updating in 2027?
The questions will need refresh as the underlying capabilities mature. By 2027 we expect live citation dashboards to be table-stakes and the discriminating questions to shift towards causal attribution (which prompts caused which sales pipeline) and cross-engine arbitrage (managing visibility across ChatGPT, Perplexity, Gemini and Bing Chat as separate surfaces). We will publish a refreshed filter set in May 2027 reflecting the new market state.
Sources and references
- UK agency directory 2025. Search Engine Land, 2025
- Agency RFP claims dataset. Ahrefs, 2025
- Companies House filings, UK 2024-25. Companies House, 2025
- ICO guidance on processing for marketing analytics. ICO, 2025
- Profound cross-industry AI citation benchmark. Profound, 2025
- GEO: Generative Engine Optimization. arXiv (Aggarwal et al.), 2024
Issuing an AI SEO RFP? Request a free GEO audit and we will score the responses you receive against this 5-question filter inside ten working days.
Change log
- 2026-05-18: Initial publication.