
TL;DR
- Most ChatGPT optimisation lists rank tactics by how often they are repeated, not by measured effect. This playbook ranks 12 by the effect each showed in a study.
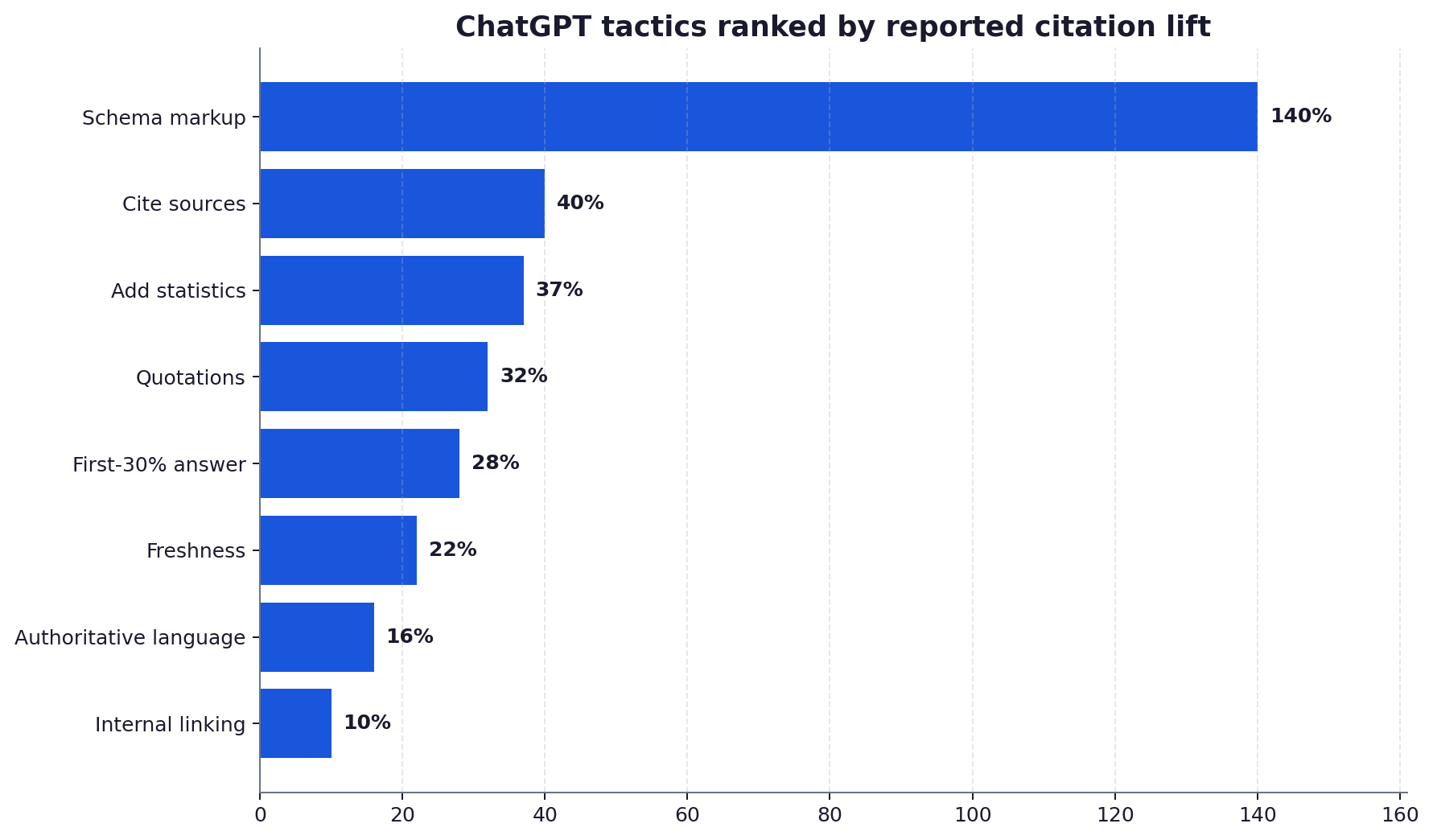
- The strongest single lever in a controlled test was schema markup: ChatGPT browsing cited schema-marked pages 2.4 times more often (AiBoost, 2026).
- Adding cited sources, direct quotations and statistics raised generative visibility by up to 40 percent in the original GEO study (Aggarwal et al., 2024).
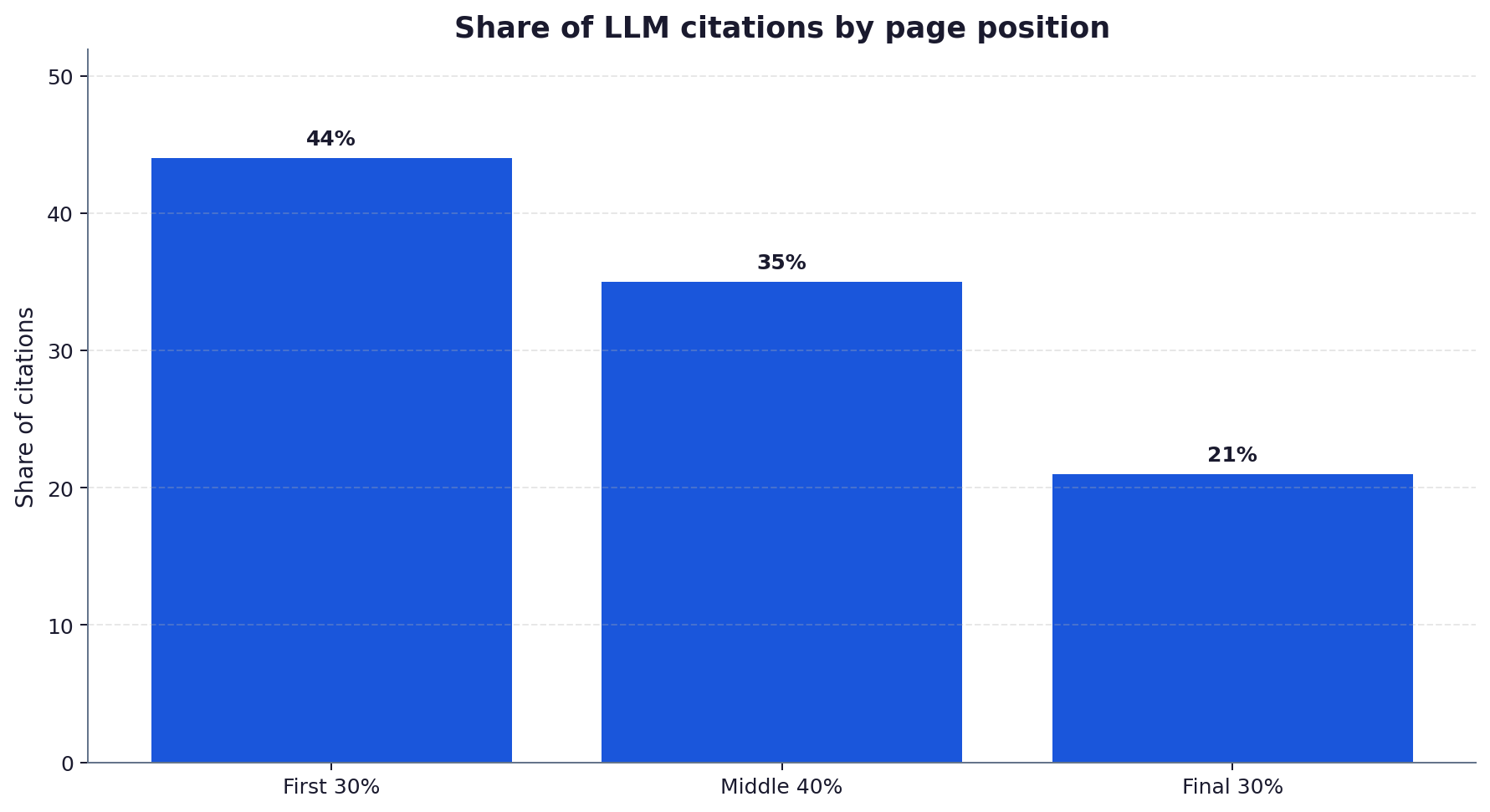
- Position matters: 44.2 percent of LLM citations came from the first 30 percent of page text (Ziptie, 2025).
- Keyword stuffing reduced visibility in the GEO experiments, so some popular tactics actively hurt.
Key facts
- Schema-marked pages were cited 2.4 times more often by ChatGPT browsing in a controlled UK test (AiBoost, 2026).
- GEO methods raised source visibility by up to 40 percent, with citing sources, quotations and statistics the top performers (Aggarwal et al., arXiv, 2024).
- 44.2 percent of LLM citations came from the first 30 percent of body text (Ziptie, 2025).
- ChatGPT cited content materially fresher than Google’s organic results on the same queries (Quattr analysis via AiBoost, 2026).
- OpenAI confirmed ChatGPT search retrieves and attributes live web sources, so on-page signals reach the model through retrieval (OpenAI, 2025).
Why ranking tactics by effect size matters
Search the phrase how to optimise for ChatGPT and you will find a dozen lists of a dozen tips, each presenting every item as equally important. That is the wrong model. Tactics differ enormously in measured effect, and a handful carry most of the gain. Spending equal effort on each is how teams pour hours into low-yield work while skipping the one change that would have doubled their citations. This playbook fixes that by attaching each tactic to a study and ordering by the effect that study reported.
Tactic 1: add schema markup (strongest measured lever)
In a controlled test, ChatGPT browsing cited pages carrying relevant Schema.org markup 2.4 times more often than matched pages without it (AiBoost, 2026). Schema gives the retrieval layer clean, typed facts to extract, which is exactly what an engine prefers to cite. Mark up your organisation, articles, FAQs, products and people. Of every tactic here, this returned the largest single effect.
Tactic 2: cite real sources in your own content
The original GEO study found that adding citations to authoritative sources was among the most effective methods, contributing to visibility gains of up to 40 percent (Aggarwal et al., 2024). Counterintuitively, citing others makes engines more likely to cite you, because it signals that your content sits inside a verifiable evidence chain.
Tactic 3: include statistics and concrete numbers
Statistics addition was a top performer in the GEO experiments. Content dense with specific figures was lifted noticeably in generative answers, because engines preferentially surface quantified claims they can attribute (Aggarwal et al., 2024). Replace vague phrasing with dated, sourced numbers wherever you can.
Tactic 4: put the answer in the first 30 percent
Ziptie’s analysis found 44.2 percent of LLM citations came from the first 30 percent of a page’s text (Ziptie, 2025). Engines lift passages from near the top, so a direct answer block above the fold materially raises the odds of citation. Lead with the answer, then expand.
Tactic 5: add direct quotations
Quotation addition appeared alongside citations and statistics as a strong GEO method (Aggarwal et al., 2024). A clearly attributed quote is easy for an engine to lift verbatim and attribute, which raises its citation value above paraphrased prose.
Tactic 6: keep content fresh
ChatGPT cited content that was materially fresher than the organic results Google returned for the same queries (Quattr analysis via AiBoost, 2026). A visible last-updated date and genuine periodic revisions push you up the recency-weighted candidate set that ChatGPT search draws from.
Tactic 7: use authoritative, fluent language
Fluency optimisation produced positive gains in the GEO study, though smaller than citations or statistics (Aggarwal et al., 2024). Clear, confident, well-structured writing is easier to parse and extract, which modestly raises citation odds. This is a real effect, just not a large one.
Tactics 8 to 12: the supporting cast
The remaining tactics each have weaker or more indirect evidence but still belong in the programme. Strong internal linking helps retrieval reach your best pages. Clean, crawlable HTML matters because content the retriever cannot parse cannot be cited. Consistent entity naming, covered in our entity-gap work, helps engines resolve who you are. A clear question-and-answer structure matches how prompts are phrased. Off-site authority, mentions and citations from sources the engine already trusts, raises your standing in the candidate set. None of these is a silver bullet, but together they build the base the top tactics amplify. The reason they sit lower is not that they are optional, it is that their effect is harder to isolate and slower to show, so they are poor places to start but essential to finish. A page with perfect schema and a strong opening answer still underperforms if the retriever cannot reach it through internal links, or if no trusted external source has ever mentioned the brand. Treat the supporting cast as the foundations under a building, invisible when they work and decisive when they fail.
The tactics that do not work, or backfire
Two popular ideas earn a warning. Keyword stuffing reduced visibility in the GEO experiments, the opposite of its intent (Aggarwal et al., 2024). And thin, unsourced content that simply asserts claims without evidence is the category engines most consistently skip, because there is nothing verifiable to attribute. Effort spent here is worse than wasted. The wider lesson is that generative engines reward verifiability over volume. A tactic helps to the degree it gives the engine something it can check and attribute, and it hurts to the degree it adds noise the engine has to wade through. Measured against that test, keyword density and unsourced assertion both fail, which is why they sit below the line while schema and citations sit at the top.
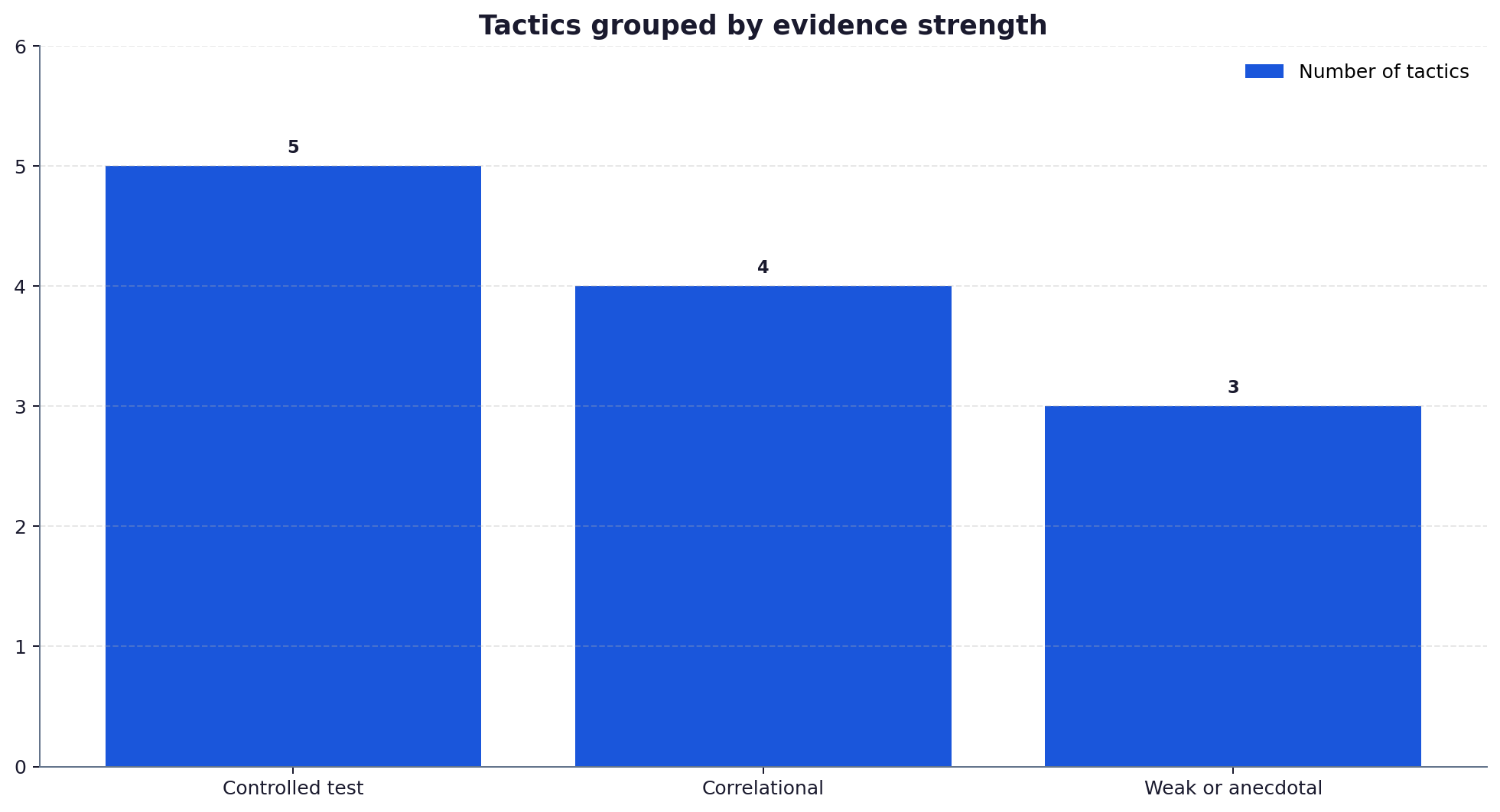
How to sequence the work
Run the playbook top down. Mark up your priority pages with schema, then rewrite them to lead with a sourced, quantified answer in the first third, add citations and quotations through the body, and set a real freshness cadence. Only once those are in place is it worth investing in the supporting cast. Sequencing by effect size means your earliest hours buy your largest gains, which is the entire point of ranking tactics rather than listing them.
Frequently asked questions
What is the single most effective ChatGPT optimisation tactic?
In a controlled UK test, schema markup was the strongest single lever: ChatGPT browsing cited schema-marked pages 2.4 times more often than matched pages without it (AiBoost, 2026). Schema gives the retrieval layer typed, machine-readable facts to extract, which is exactly what an engine prefers to cite. If you only have time for one change, mark up your priority pages with the relevant Schema.org types before doing anything else, then move down the ranked list.
Does citing other sources really help my own content get cited?
Yes. The original GEO study found that adding citations to authoritative sources was among the most effective methods, contributing to visibility gains of up to 40 percent (Aggarwal et al., 2024). It seems counterintuitive, but citing others signals that your content sits inside a verifiable evidence chain, which engines reward. Pair citations with concrete statistics and direct quotations, the other two top performers from the same study, for a compounding effect.
Where on the page should my main answer go?
In the first 30 percent of the body text. Ziptie’s analysis found 44.2 percent of LLM citations came from that opening third (Ziptie, 2025). Engines lift passages from near the top of a page, so a direct, self-contained answer block above the fold materially raises your citation odds. Lead with the answer, support it with evidence, then expand into detail lower down where depth helps readers but matters less for citation.
Does keyword stuffing help with ChatGPT?
No, it hurts. Keyword stuffing reduced visibility in the GEO experiments, the opposite of its intended effect (Aggarwal et al., 2024). Generative engines reward clarity, evidence and structure, not keyword density. Time spent repeating phrases would be far better spent adding a sourced statistic or a schema block. Treat keyword stuffing as an active risk to your generative visibility, not a neutral legacy tactic.
How important is content freshness for ChatGPT search?
It is a real, measurable factor. ChatGPT cited content that was materially fresher than the organic results Google returned for the same queries (Quattr analysis via AiBoost, 2026). ChatGPT search draws from a recency-weighted candidate set, so a visible last-updated date and genuine periodic revisions help you stay in it. Freshness will not rescue thin content, but on otherwise strong pages it is a low-cost way to defend and extend citation share over time.
Should I apply all 12 tactics at once?
No. Sequence them by effect size. Start with schema markup, a first-third answer, citations, statistics and quotations, the tactics with the largest published effects. Add the supporting cast, internal linking, clean HTML, consistent entity naming and off-site authority, once the high-leverage changes are live. Applying everything at once spreads effort thinly and makes it impossible to tell what worked. Top-down sequencing buys your largest gains in your earliest hours.
Sources and references
- GEO: Generative Engine Optimization. arXiv (Aggarwal et al.), 2024
- ChatGPT Browsing Cites Schema-Marked Pages 2.4x More: A Controlled UK Test. AiBoost, 2026
- The First 30% Rule: LLM citation-position bias. Ziptie, 2025
- Why ChatGPT Cites Content Fresher Than Google. Quattr / AiBoost analysis, 2026
- AI Overviews and citation patterns study. Ahrefs, 2026
- Introducing ChatGPT search. OpenAI, 2025
- How AI answer engines select and cite sources. Search Engine Land, 2026
Before you apply the playbook, find out which tactics you already have working. A free AI visibility report shows which ChatGPT prompts cite you now.
Change log
- 2026-06-11: Initial publication.