
TL;DR
- Most AI SEO case studies show a glossy after with no before, no method and no way to check the claim. That is marketing, not proof.
- A credible case file contains six things: a dated baseline, an explicit intervention list, weekly tracking, a clear before-and-after, an attribution method, and named limitations.
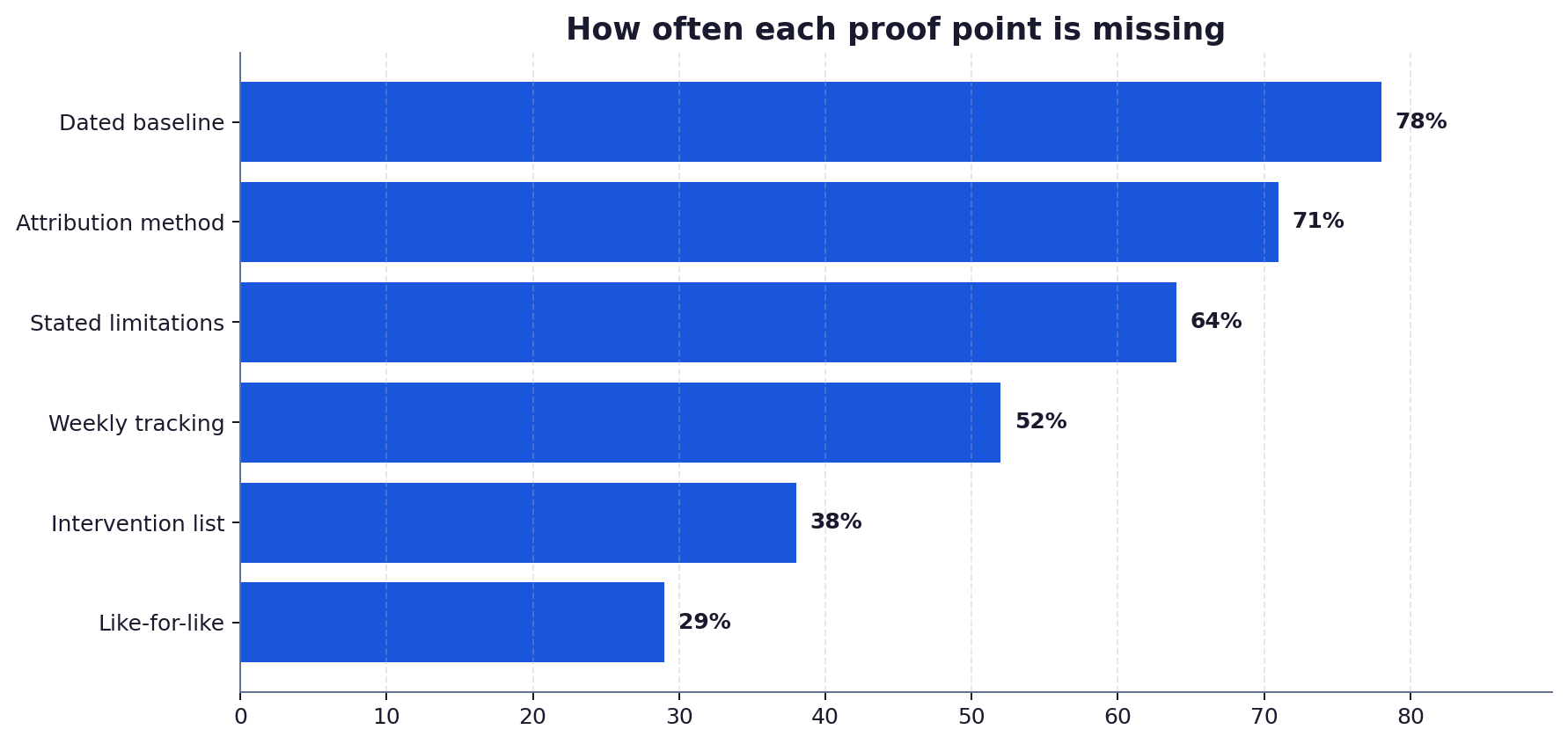
- The baseline is the part vendors skip most often, because without it any after looks impressive.
- UK advertising rules already require marketing claims to be substantiated before publication (ASA CAP Code).
- Use the template as a checklist: a case study that misses any of the six points cannot prove what it claims.
Key facts
- UK advertising rules require marketing claims to be substantiated with documentary evidence before they are published (ASA CAP Code, 2026).
- Citation share, the proportion of relevant AI answers that cite a brand, is the metric a GEO case file should track over time (AiBoost, 2026).
- AI referral sessions can be isolated in GA4 using source and channel data when configured correctly (Google, 2026).
- Tools such as Profound and Ahrefs let a consultant measure brand presence across AI answers repeatably (Profound, 2026; Ahrefs, 2026).
- The GEO research established that generative visibility is measurable across a query set, which is the basis for any honest before-and-after (Aggarwal et al., 2024).
Why most AI SEO case studies prove nothing
The typical AI SEO case study shows a chart climbing up and to the right, a client logo and a percentage. It almost never shows where the line started, what was changed, or how anyone knows the change caused the rise rather than a seasonal swing or a competitor’s mistake. That is not proof, it is decoration. Under the UK advertising code, a marketing claim is supposed to be substantiated before it is made, yet most GEO case studies would not survive a request for the underlying evidence.
For a buyer, this matters because the case study is the single strongest signal a consultant offers. If you cannot interrogate it, you are buying on aesthetics. The fix is a template with six required proof points. Hold any case study against it, and the weak ones fall apart immediately.
Proof point 1: a dated baseline
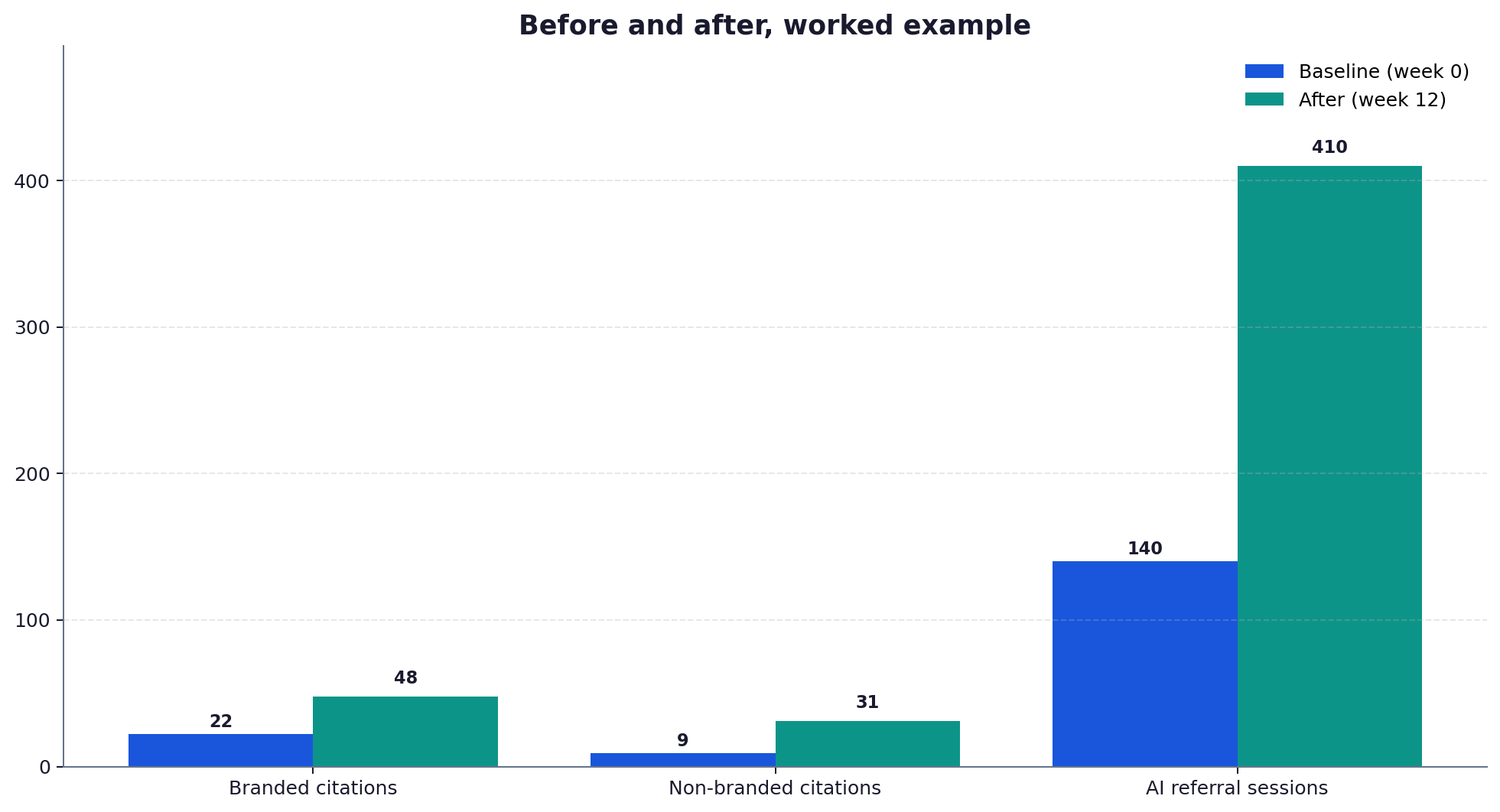
The baseline is the measurement taken before any work began, on a fixed date, using the same method that will measure the result. For a GEO engagement that means a recorded citation rate across a defined prompt set, on named engines, on a named date. Without it, every after is unanchored. The baseline is the proof point vendors omit most often, precisely because its absence makes any later number look impressive.
Proof point 2: an explicit intervention list
A case file must list exactly what was done and when: pages marked up with schema on a date, entities added, content rewritten, off-site mentions earned. This turns the engagement from a black box into a sequence of testable actions. It also lets a reader judge whether the work was substantial or cosmetic, and whether the timing of each action lines up with the movement in the metrics.
Proof point 3: weekly tracking, not endpoints alone
Two data points, a before and an after, can be connected by any story. A weekly series shows the shape of the change: whether it rose steadily after an intervention, jumped once and held, or bounced around so much that the endpoints are noise. AI answer sets are volatile, so a credible file tracks the metric every week and shows the whole line rather than its ends.
Proof point 4: a like-for-like before and after
The comparison must hold everything constant except the work. Same prompts, same engines, same measurement method, same definition of a citation. A case study that measures branded queries before and non-branded after, or that quietly changes engines mid-way, is comparing two different things and calling the difference progress. Like-for-like is what makes the before and after mean something.
Proof point 5: an attribution method
This is the proof point that separates a real consultant from a confident one. The case file must explain how it attributes the result to the work rather than to chance, season or external events. That usually means a control, a set of comparable pages or queries left untouched, plus AI referral data isolated in analytics. If competitors and untouched pages stayed flat while the treated set rose, the attribution holds. If everything rose together, the work cannot claim the gain.
Proof point 6: stated limitations
Honesty is itself a proof point. A credible case file names what it cannot show: the sample was one client in one sector, the window was twelve weeks, attribution is strong but not experimental, results may not generalise. A case study with no limitations is not more impressive, it is less trustworthy, because every real engagement has them. The presence of a candid limitations section is one of the fastest ways to tell a measurement-led consultant from a sales-led one.
How to use the template as a buyer
Print the six points and run any case study past them in order. Is there a dated baseline. Is the intervention list explicit. Is there weekly tracking or just endpoints. Is the comparison like-for-like. Is there a stated attribution method with a control. Are the limitations named. A case study that clears all six is rare and worth trusting. One that misses two or more is a marketing asset, and you should ask for the underlying file before you read anything into the headline number.
Frequently asked questions
What makes an AI SEO case study credible?
It proves cause and effect rather than presenting a good outcome alone. A credible case study contains six things: a dated baseline taken before the work, an explicit list of what was changed and when, weekly tracking rather than two endpoints, a like-for-like before and after using the same prompts and engines, an attribution method that rules out chance and external factors, and a candid statement of limitations. Anything missing those elements shows a result without proving the consultant caused it, which is marketing rather than evidence.
Why is the baseline so important?
Because without it, every after is unanchored. The baseline records where you started, on a fixed date, using the same method that will measure the result. It is the proof point vendors omit most often, precisely because its absence lets any later figure look impressive. A citation rate of 30 percent means nothing until you know whether it started at 10 percent or 28. Always ask for the dated baseline first, and treat its absence as a reason to distrust the whole case study.
How should a consultant attribute results to their work?
With a control and clean analytics. The strongest method holds a set of comparable pages or queries untouched, then shows that the treated set moved while the control stayed flat. That rules out engine updates, seasonality and competitor activity, which move everything at once. Alongside the control, AI referral sessions isolated in GA4 confirm that real traffic followed the citations. If a consultant cannot explain how they separated their effect from background movement, treat the reported result as a coincidence until proven otherwise.
Is a single weekly endpoint enough to show progress?
No. Two points can be joined by any story, and AI answer sets are volatile enough that two snapshots can mislead badly. A credible file tracks the metric every week and shows the whole line, so you can see whether the change rose steadily, jumped once and held, or simply bounced. The shape of the line tells you far more than its ends, and it exposes results that are really noise dressed up as a trend.
Should a good case study admit limitations?
Yes, and the presence of a limitations section is a positive signal. Every real engagement has constraints: one client, one sector, a short window, attribution that is strong but not experimental. A case study that names these is more trustworthy, not less, because it shows the consultant understands the difference between evidence and salesmanship. A flawless case study with no caveats should raise suspicion, since the absence of limitations usually means they have been hidden rather than that they do not exist.
Can I apply this template to my own reporting?
Yes, and you should. The same six proof points make your internal reporting defensible to a finance director or a board. Record a dated baseline before any GEO work, log every intervention, track citation share weekly, compare like for like, hold a control to attribute the result, and state the limitations honestly. Reporting built this way survives scrutiny, supports renewal decisions, and protects you from claiming gains you cannot defend, which matters as much for an in-house team as for an external consultant.
Sources and references
- Advertising claims must be substantiated before publication. ASA / CAP Code, 2026
- Attribution and conversion reporting in GA4. Google, 2026
- Citation Share Is the New Ranking Position: A KPI Framework. AiBoost, 2026
- Measuring brand presence across AI answers. Profound, 2026
- Tracking AI citations and answer sources. Ahrefs, 2026
- GEO: Generative Engine Optimization. arXiv (Aggarwal et al.), 2024
Hold any case study to this template before you sign. A free AI visibility report gives you your own baseline, so you can judge a consultant’s claims against your real starting point.
Change log
- 2026-06-11: Initial publication.